
Chinese AI startup DeepSeek has released an upgraded version of its flagship reasoning model, DeepSeek-R1-0528, as an open-source update to the original R1 model. Although described by the company as a “small version upgrade,” early tests indicate major leaps in capability, especially in complex reasoning, coding tasks, and overall reliability.
The new model leverages increased computational resources and algorithmic optimizations in its post-training stage (primarily reinforcement learning fine-tuning) to significantly deepen its reasoning and inference abilities. As a result, DeepSeek-R1-0528 now rivals leading proprietary models on many benchmarks – its performance is approaching that of OpenAI’s “O3” model and Google’s Gemini 2.5 Pro. Like its predecessor, R1-0528 is fully open-sourced under an MIT license, with model weights and code available for the community. This open release enables AI researchers to scrutinize the model and even reuse its outputs for further research and fine-tuning, a level of openness that contrasts with most top-tier closed models.
Architecture and Core Advancements
Under the hood, DeepSeek-R1-0528 retains the same innovative architecture introduced with R1. It is built on DeepSeek’s third-generation base model (DeepSeek-V3), a Mixture-of-Experts (MoE) transformer with an enormous scale – roughly 671 billion total parameters (with ~37B active per token inference). This sparse MoE design allows the model to achieve extreme scale while keeping inference efficient, since only a subset of experts activates for each input token.
The model also supports a long context window up to 128,000 tokens (tested up to 164K in some cases), far exceeding the few-thousand-token context limits of earlier generation models. This means R1-0528 can ingest and reason over very large documents or code bases in a single session, which is crucial for complex multi-step reasoning and code generation tasks.
DeepSeek’s training pipeline is a key differentiator. The original R1 was developed through large-scale Reinforcement Learning (RL) fine-tuning on top of the pre-trained DeepSeek-V3 base, with minimal supervised data. In fact, the team first built “DeepSeek-R1-Zero” purely via RL (no supervised fine-tuning), demonstrating that advanced reasoning behaviors can emerge without any human-labeled examples. R1-Zero exhibited impressive reasoning but suffered issues like incoherent formatting and mixed languages.
To address this, the final DeepSeek-R1 introduced a small “cold start” supervised dataset (on the order of thousands of curated Q&A pairs) before RL, and then a multi-stage RL procedure to refine reasoning and align outputs to human-preferred style. This multi-stage training (a couple of supervised fine-tuning passes interleaved with two RL phases) produced a model that achieved performance on par with OpenAI’s reference model (code-named o1 in DeepSeek’s reports) across math, coding, and logic benchmarks. Source
DeepSeek-R1-0528 builds on this foundation with further optimizations in the RL fine-tuning stage. According to the official release notes, the new version applied additional compute and new RL algorithmic strategies during post-training to boost the depth of the model’s reasoning. In practical terms, R1-0528 can carry out much longer and more elaborate chains-of-thought than before.
For example, during a math reasoning evaluation, the previous R1 would use on average ~12K tokens of step-by-step reasoning for each problem, whereas R1-0528 now generates around 23K tokens of reasoning per question, reflecting a substantially deeper thinking process. Despite the upgrade, the model’s architecture (number of parameters, MoE structure, context length) remains the same as the prior version – the improvements come from better training techniques rather than a larger model. Notably, DeepSeek researchers did not introduce a massive new supervised dataset for this version, but instead focused on refining the reinforcement learning and alignment process to unlock more capability from the existing model. (In earlier research they even added a language consistency reward during RL to prevent the model from mixing languages in its answers, since R1 is primarily optimized for English and Chinese. This helps ensure the model responds in one language at a time, an important consideration for multilingual settings.)
Performance Improvements and Benchmarks
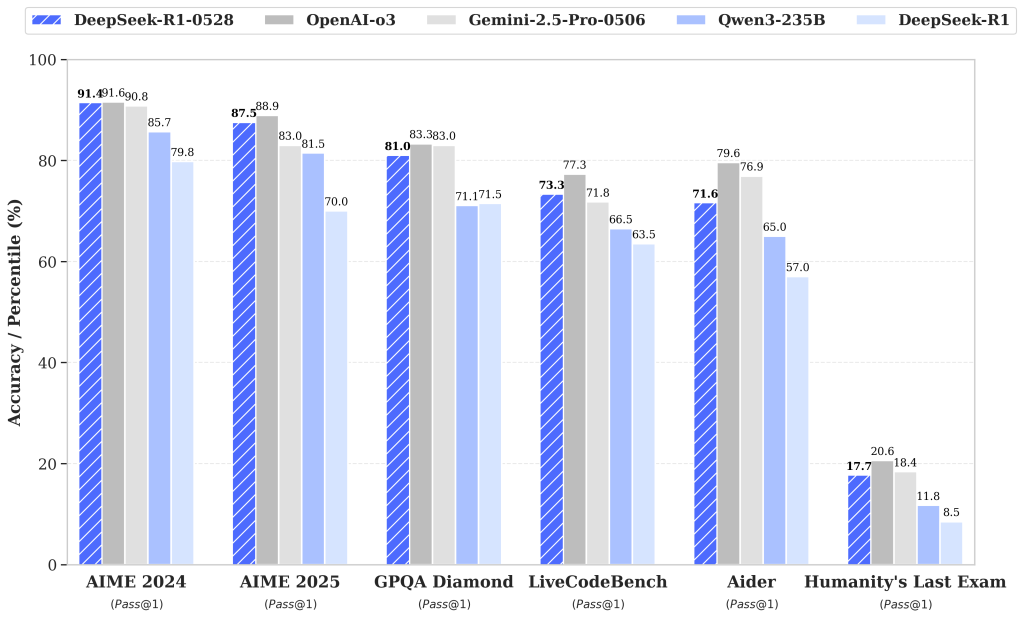
Figure: Benchmark results for the upgraded DeepSeek-R1-0528 (blue striped bars) compared to the original DeepSeek-R1 (solid light-blue) and competing models: OpenAI’s “O3” (gray) and Google’s Gemini 2.5 Pro (dark bars). The chart shows accuracy or Pass@1 on various tasks: math contests (AIME 2024/2025), a general QA test (GPQA Diamond), coding challenges (LiveCodeBench, Aider), and a difficult logic exam (“Humanity’s Last Exam”). DeepSeek-R1-0528 substantially closes the gap to O3 and Gemini on these evaluations.
Across a wide array of benchmarks, DeepSeek-R1-0528 demonstrates significant performance gains over the initial R1 model. On mathematical reasoning tests, the improvement is especially dramatic. For instance, on the 2025 AIME math competition problems, the original model solved 70% of questions, whereas R1-0528 now solves 87.5% – a jump that approaches the top-tier proprietary models’ accuracy on this test. This boost in math performance stems from the model’s enhanced chain-of-thought depth and consistency.
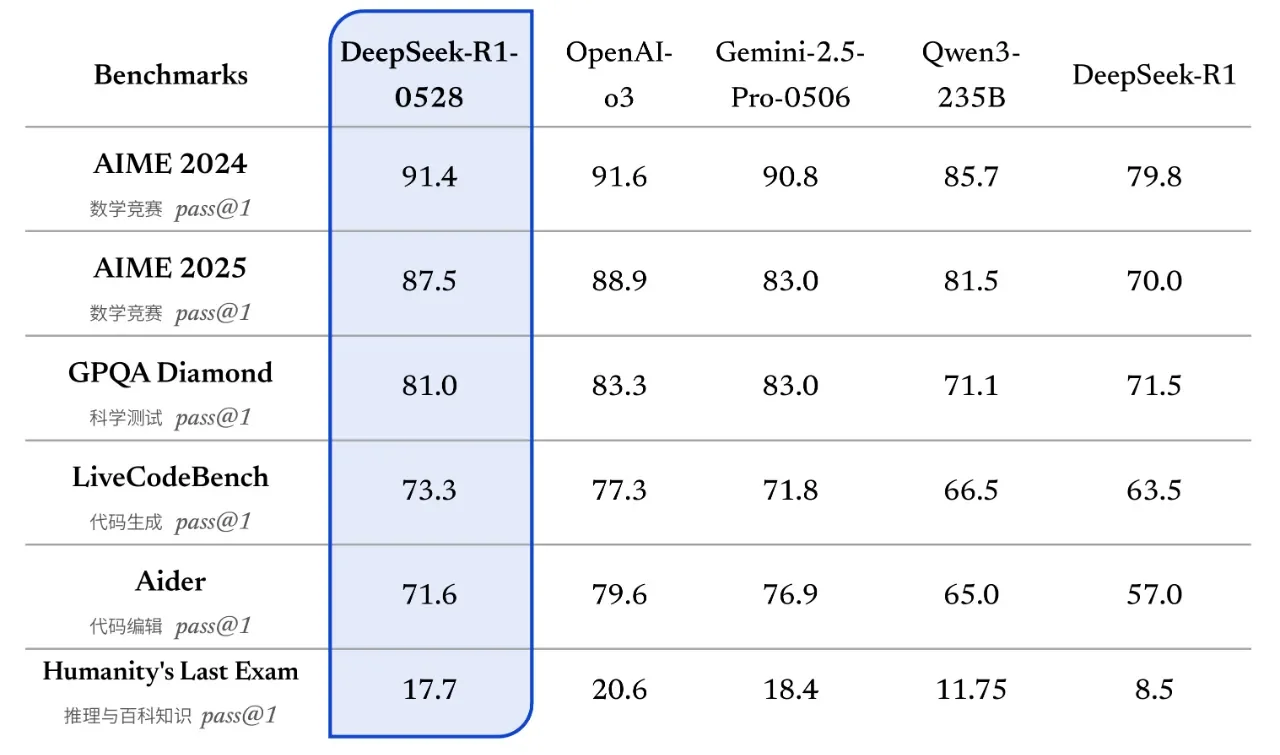
Similarly, on the HMMT 2025 math challenge, the upgraded model answered nearly 79% of questions correctly, up from about 42% before – an almost twofold improvement, turning a mid-tier performance into one rivalling the best open models. General reasoning and knowledge tests saw more modest but still notable gains; for example, a complex QA benchmark (GPQA “Diamond”) rose from ~71.5% to 81.0% accuracy. Even a notoriously difficult evaluative set dubbed “Humanity’s Last Exam” (a broad challenge of knowledge and logic) saw the model’s score roughly double (from 8.5 to 17.7), though it remains low in absolute terms as this test is extremely challenging.
The most publicized improvements are in programming and code generation, where DeepSeek-R1-0528 now performs at a level close to state-of-the-art closed models. On the LiveCodeBench coding competition (a public leaderboard for live coding challenges), R1-0528’s Pass@1 score jumped to 73.3%, up from ~63.5% with the previous R1. This places it 4th overall on the LiveCodeBench leaderboard as of its release, just shy of OpenAI’s O3 model (which scored 75.8%) and not far behind an “O4-mini” variant (80.2%) that tops that chart. Achieving over 73% on this benchmark means DeepSeek’s open model has essentially matched the coding proficiency of some of the best proprietary models in the world on non-trivial programming tasks.
Other coding benchmarks echo this trend: R1-0528 markedly improved its Codeforces competitive programming rating (now ~1930, up from 1530) and solved significantly more software engineering problems in the SWE Verified suite (57.6% vs 49.2% before). Anecdotal tests by developers have further reinforced these gains – early users report that R1-0528 can generate thousands of lines of clean, working code for complex applications in one go, often outpacing even GPT-4 (OpenAI) or Claude 4 (Anthropic) in level of detail and correctness for certain tasks. For example, when challenged to produce a 3D physics simulation with graphics, DeepSeek’s new model not only wrote more lines of code than Claude-4 but also included more sophisticated visual effects and interface elements, indicating a deeper “understanding” of the requirements.
Crucially, these advances come without sacrificing reliability. In fact, the update specifically targeted some weaknesses of the prior version. Hallucination rates are noticeably reduced in R1-0528, according to the developers, meaning the model is less likely to fabricate incorrect facts or stray off-topic. The model’s answers show improved consistency and correctness, thanks in part to the refined training which rewards accuracy and coherence. Additionally, the new version has better support for structured outputs and tool use. It can more reliably follow instructions for function calling and JSON-formatted output, which is important for applications where the model needs to return data in a specific schema. This was achieved by fine-tuning the model’s behavior to adhere to precise output formats when required. Another area of improvement is what the team calls “vibe coding” – essentially the model’s capability in collaborative or context-aware coding scenarios (for instance, generating front-end code with style or maintaining a certain coding “vibe” throughout a session). R1-0528 provides a better experience in these creative coding tasks, likely due to the model’s longer context handling and the alignment tweaks that make it more responsive to user intent.
Comparison with the Previous DeepSeek-R1
The release of R1-0528 (internally versioned as “R1.1” by some accounts) is a technical refinement of DeepSeek’s first-generation reasoning model rather than an entirely new generation. The base model architecture remains the same 671B-parameter MoE Transformer as DeepSeek-R1, and it’s built on the same pre-trained DeepSeek-V3-Base that was introduced in late 2024. In other words, R1-0528 did not expand the model’s size or ingest a large new corpus of training data compared to R1 – the training dataset (about 14.8 trillion tokens for pre-training, plus the additional reasoning datasets) and tokenization remain unchanged.
Instead, the differences lie in how the model was fine-tuned and optimized after pre-training. The original R1 already pioneered a multi-stage fine-tuning approach (two rounds of supervised fine-tuning and two of RL) to inject strong reasoning capabilities. The R1-0528 update essentially adds an extra round of improvements on top of that: the team ran extra reinforcement learning cycles (and possibly more preference model updates) to further push the model’s reasoning depth, and they introduced new reward heuristics (“algorithmic optimization mechanisms” in RL) to guide the model’s behavior more effectively. The result is that R1-0528 can solve problems the original R1 struggled with, using the same architecture.
For example, many complex math or coding problems that required extensive step-by-step reasoning are now within reach, thanks to the model’s increased “patience” and coherence in following through long reasoning chains.
In terms of capabilities, nearly every aspect of performance sees an uptick: quantitative reasoning, coding, logical Q&A, etc., as detailed above. The model’s ability to handle multi-step interactions and to utilize tools (like external APIs or function calls) also improved, owing to targeted fine-tuning for those skills. One specific enhancement is the aforementioned support for JSON outputs and function-call style prompts, which was minimal in the initial R1 but is explicitly reinforced in R1-0528 to facilitate integration into software workflows. The only area that did not see much explicit update is multilingual performance. DeepSeek-R1 has been primarily optimized for English (and Chinese, given the project’s origin) and was known to sometimes mix languages or fall back to English when given non-English prompts. In the original model, engineers mitigated this by adding a reward to keep the output in the target language. R1-0528 did not introduce new multilingual training data, so it likely maintains a similar level of multilingual capability as its predecessor – very strong in English and Chinese, but with the potential for inconsistent behavior in less-supported languages. There is no evidence of a broad multilingual evaluation improvement in this update, as the focus was chiefly on reasoning and coding quality.
Another important point of comparison is operational efficiency and accessibility. Thanks to the MoE design and training optimizations, DeepSeek-R1 was touted as achieving GPT-4-level reasoning at a fraction of the inference cost. The R1-0528 update continues this trend. It does demand hefty resources for deployment (the full model is over 700 GB in FP16 weights), but companies like DeepSeek and community projects have provided quantized versions to reduce the memory footprint (reportedly compressing the model to ~185 GB with minimal performance loss via 1.8-bit quantization). This means that, unlike closed models, researchers can actually run and profile the model on their own hardware if they have sufficient resources, or use community APIs at relatively low cost.
The open-source nature of R1-0528 cannot be overstated: the model and even its training reward datasets and generated chain-of-thought outputs are open. The company explicitly permits using the model’s outputs for any purpose, including to fine-tune other models, which opens the door for derivative research.
In conjunction with the R1-0528 release, DeepSeek also published distilled versions of the model: they successfully transferred the lengthy chain-of-thought reasoning from the 671B model into a smaller 8B parameter model (based on Qwen-3), dubbed DeepSeek-R1-0528-Qwen3-8B. Despite its much smaller size, this distilled model achieves state-of-the-art performance among open models of its scale, even matching a 235B model’s performance on certain benchmarks like AIME 2024. Such efforts highlight the progress in making advanced reasoning AI more accessible: researchers can either use the massive R1-0528 model directly, or study its distilled offspring to understand how high-level reasoning patterns can be compressed.
Conclusion and Outlook
The launch of DeepSeek-R1-0528 marks a significant milestone in the AI research community’s push toward open, advanced reasoning models. In just a few months since the original R1’s debut, DeepSeek has demonstrated that iterative reinforcement learning fine-tuning can yield rapid performance gains without changing the underlying model size.
The R1-0528 model showcases frontier-level capabilities in mathematical reasoning and code generation, putting it in close contention with the best models from OpenAI and Google on several public benchmarks. For AI researchers, this release provides not only a powerful model to experiment with, but also valuable insights through its open technical report and training data. It underscores a trend of openness in cutting-edge AI: by open-sourcing a model of this caliber, DeepSeek enables researchers to inspect its outputs (e.g. its long chain-of-thought solutions), identify strengths and weaknesses, and build upon its techniques.
Moving forward, the improvements seen in DeepSeek-R1-0528 hint at what might come next. The company’s roadmap likely involves a true “R2” model in the future, potentially building on the lessons of R1’s reinforcement learning paradigm.
In the meantime, R1-0528’s release narrows the performance gap between open models and closed models, which could drive more collaborative innovation in the field. Researchers can use R1-0528 as a benchmark for developing new fine-tuning strategies, testing reasoning in extremely large contexts, and exploring multi-step problem solving in AI.
With its high performance and permissive licensing, DeepSeek-R1-0528 stands out as a state-of-the-art open platform for advanced AI reasoning research, inviting the community to push it even further. The competition between open-source and proprietary AI has clearly intensified, and R1-0528 shows that an open model can hold its own alongside the titans of AI – an exciting prospect for the future of accessible, transparent AI development.



