DeepSeek-VL is a powerful open-source vision-language (VL) model designed to understand and reason about visual data in combination with natural language.
Announced in 2024, DeepSeek-VL emerged to tackle the growing demand for AI systems that can handle multiple modalities – much like OpenAI’s GPT-4 Vision or Google’s Gemini, but in an open and accessible manner.
What sets DeepSeek-VL apart is its focus on real-world vision-language understanding: it’s built not just for captioning images, but for interpreting complex visuals like diagrams, charts, webpages, and more in practical scenarios.
This model bridges the gap between pure language models and the visual world, enabling applications that require seeing and reading images, then integrating that information with text-based reasoning.
In this article, we’ll dive into DeepSeek-VL’s capabilities, its underlying architecture, how it compares to leading multimodal AI models, and the innovative use cases it unlocks.
Capabilities and Use Cases of DeepSeek-VL
DeepSeek-VL possesses general multimodal understanding capabilities far beyond simple image captioning.
It has been trained and tuned to handle a wide array of vision-language tasks, making it a versatile AI assistant in scenarios that involve interpreting visual content alongside text.
Key capabilities include:
- Visual Question Answering (VQA): DeepSeek-VL can answer questions about images – for example, identifying objects, describing scenes, or explaining what is happening in a picture. Given an image and a related question, it generates contextually accurate answers. It handles everyday photos as well as specialized images (e.g. medical images or technical diagrams) by leveraging its broad training data.
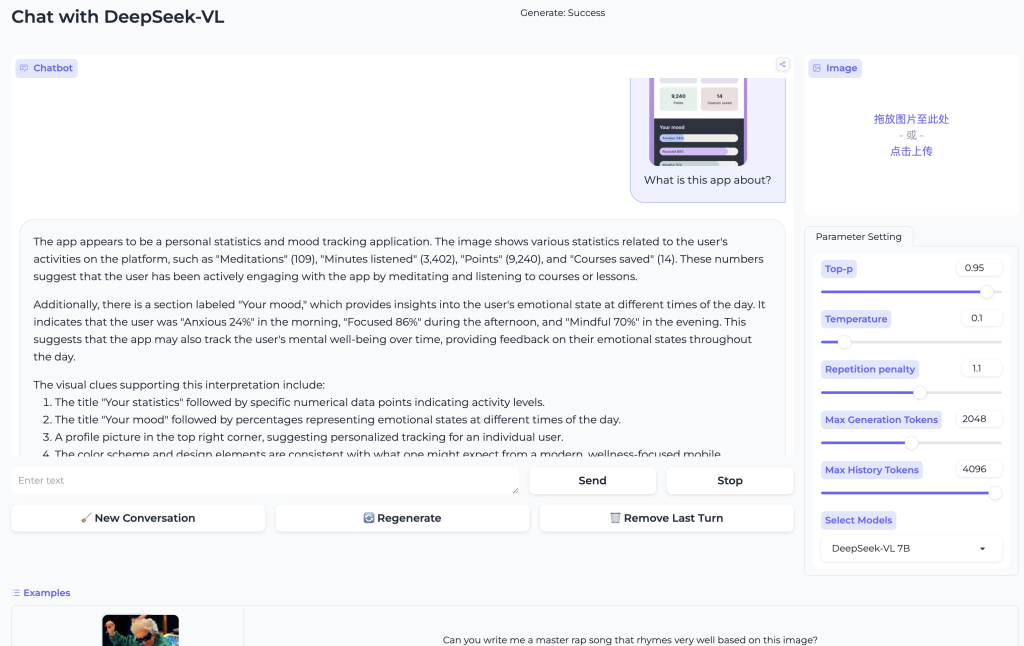
- Optical Character Recognition and Text Understanding in Images: The model is adept at reading and comprehending text within images. Whether it’s a screenshot of a webpage, a photo of a street sign, or a scanned document, DeepSeek-VL can extract text via OCR and interpret its meaning. It can, for instance, summarize a PDF page image or answer questions about the content of a chart or table in an image. This makes it valuable for tasks like processing scanned documents, digitizing information from images, or assisting users with visual impairments by reading aloud text from the environment.
- Document and Chart Analysis: Unlike many vision models limited to photos, DeepSeek-VL specifically targets real-world documents and graphical data. It can parse charts, tables, forms, and infographics embedded in images. For example, it could examine a bar graph in an image and explain the trends, or look at an invoice PDF and extract key fields. This capability is crucial for business applications (automating data entry from images, analyzing reports) and for research (reading scientific plots or diagrams). In tests, DeepSeek-VL has demonstrated strong performance on document understanding benchmarks, rivaling or beating specialized OCR systems at the same model size.
- Logical Diagrams and Web Pages: The model’s training encompassed logical diagrams and web page screenshots, meaning it can interpret UI elements or schematic diagrams. For instance, it might take a screenshot of a website and identify different sections or buttons, useful for UI automation or accessibility tools. It can also reason about flowcharts or network diagrams by analyzing their structure. These abilities are uncommon among vision-language models, underscoring DeepSeek-VL’s orientation toward practical, diverse inputs.
- Embodied and Real-World Scenarios: DeepSeek-VL is designed with an eye on robotics and “embodied AI” scenarios. This means it can handle inputs like an agent’s egocentric view (what a robot or AR glasses sees) and follow instructions related to that. For example, given an image of a kitchen from a home robot’s camera, DeepSeek-VL could understand the scene (“there are dishes in the sink and a refrigerator to the right”) and answer questions or give suggestions (“the sink is full; perhaps start by loading the dishwasher”). This capability to interpret complex, real-world scenes and relate them to action or instructions is key for future AI assistants that operate in physical environments.
Use Case Examples:
DeepSeek-VL’s versatility is illustrated above with examples of its multimodal reasoning.

It can identify specific objects in images, interpret floor plan layouts, describe artworks in context, translate formulas from a snapshot into LaTeX, and even convert a flowchart into code.
Thanks to such wide-ranging skills, DeepSeek-VL opens up innovative use cases across industries:
- Education: Imagine an app where a student can photograph a complex geometry diagram or chemistry experiment setup and ask questions; DeepSeek-VL could provide explanations or solutions, functioning as a visual tutor.
- Business: Companies can use it to automate processing of forms, receipts, and slides – feeding in scanned files and letting the model output structured data or summaries. It could also power advanced virtual assistants that handle both text and image queries (e.g., “Look at this dashboard screenshot – what was our sales trend last quarter?”).
- Healthcare: DeepSeek-VL could assist doctors by analyzing medical charts or lab report images and answering questions, or help patients by explaining information on a prescription label or medical brochure image.
- Accessibility: For visually impaired users, DeepSeek-VL can serve as the core of tools that narrate the visual world – reading text from images, describing surroundings, or interpreting signs and screens, thus making digital and physical content more accessible.
Architecture and Innovations
Developing a model that excels in both vision and language is challenging, and DeepSeek-VL incorporates several architectural innovations and training strategies to achieve this:
- Hybrid Vision Encoder for High Resolution: DeepSeek-VL uses a custom hybrid vision encoder that can efficiently handle high-resolution images up to 1024×1024 pixels. Many prior multimodal models (especially open-source ones) were limited to lower resolution inputs (such as 224×224 or 448×448 pixels) due to model size and computational constraints. That resolution is often insufficient for tasks like reading small text (OCR) or spotting tiny details in diagrams. In contrast, DeepSeek’s encoder is designed to process 1024px images within a fixed token budget while keeping computational cost relatively low. This likely involves a combination of patch-based image encoding and selective processing (e.g., focusing on salient regions) to avoid exploding the token count. The result is an architecture that captures fine-grained visual information (small text in a chart, tiny objects in a photo) without overwhelming the language model part with too many visual tokens. This high-res capacity is a major differentiator in real-world performance, enabling DeepSeek-VL to outperform models that miss critical details due to image downsampling.
- Integration of Vision and Language Training: A key insight from DeepSeek AI’s research is that a great vision-language model must first and foremost be a strong language model. They observed that many multimodal training approaches, if not carefully managed, can degrade a model’s core language abilities (since the model shifts focus to image features). DeepSeek-VL’s training strategy was novel: from the very start of pretraining, it integrated language modeling with vision, and gradually increased the proportion of image+text data vs. pure text data. Early on, the model spent more time learning to be an excellent text generator (leveraging techniques similar to training an LLM). Then, visual inputs were introduced in a balanced way, ensuring the model learned to fuse modalities without forgetting its language mastery. This balanced curriculum and careful management of the “competition” between vision and language training signals allowed DeepSeek-VL to maintain robust language skills while learning vision. The end result is a model that can discuss an image’s content in fluent, coherent language, just as well as it can handle non-visual text tasks – avoiding the common pitfall where a VL model might underperform on pure text compared to its unimodal counterpart.
- Model Sizes and Variants: The initial release of DeepSeek-VL (March 2024) provided two main sizes – approximately 1.3 billion and 7 billion parameters – each with a base and a chat-tuned variant. The base models are pretrained on multimodal data (images + text) and are useful for further fine-tuning, while the chat models have been instruction-tuned for conversational use (they are more aligned to follow user prompts and produce helpful answers). Despite the relatively moderate size of these models, their performance was strong; the 7B DeepSeek-VL model achieved state-of-the-art or competitive results on many benchmarks when compared to other models in its class (for instance, matching or beating larger dense models on tasks like VQA, according to the project’s paper). This shows the effectiveness of the architecture and training approach. Moreover, the DeepSeek team open-sourced all variants, including training code and even demo notebooks on Hugging Face for easy experimentation.
- DeepSeek-VL2 – MoE Enhanced: Building on the success of DeepSeek-VL, the team introduced DeepSeek-VL2 in late 2024 as an advanced series using Mixture-of-Experts (MoE) in the vision-language domain. This approach mirrors the DeepSeek-LLM’s MoE strategy: instead of one giant dense model, VL2 uses multiple expert sub-models that are conditionally activated. The released VL2 family includes variants like DeepSeek-VL2-Tiny, -Small, and the full DeepSeek-VL2, with 1.0B, 2.8B, and 4.5B activated parameters respectively. Despite the seemingly smaller active size, these MoE models achieve equal or better performance than much larger dense models, thanks to specialized experts for different tasks. For example, one expert might specialize in OCR while another in object recognition, and the model routes inputs to the appropriate expert, improving efficiency and results. DeepSeek-VL2 demonstrates superior capabilities in visual question answering, OCR, document understanding, and visual grounding – effectively surpassing the original DeepSeek-VL and many contemporary models in those tasks. The introduction of MoE in vision-language models was relatively novel, and it allowed scaling the model’s capacity without a proportional increase in inference cost. VL2’s success underlines DeepSeek’s commitment to pushing open-source multimodal AI forward with state-of-the-art techniques.
Performance and Benchmark Comparisons
Evaluations of DeepSeek-VL have shown that it delivers state-of-the-art or highly competitive performance on a broad array of benchmarks, especially when considering its model size.
According to the DeepSeek-VL research paper, the 7B model achieves or exceeds the performance of other models in its class across many public datasets.
Some notable points of comparison and performance include:
- Vision-Language Benchmarks: On standard VQA datasets (like VQAv2, OK-VQA), DeepSeek-VL’s accuracy is on par with the best open models of similar size, demonstrating solid understanding of general images. On more specialized benchmarks such as DocVQA (document visual QA) or TextVQA (text in images), it excels due to its high-resolution OCR capability – often outperforming models that don’t handle high-res text well. It also shows strong results in visual reasoning benchmarks like NLVR2 (reasoning about paired images) and chart QA, reflecting its broad training on diagrams and charts.
- Language Benchmarks: Importantly, DeepSeek-VL retains strong language-only performance. The team evaluated it on traditional NLP benchmarks (WikiQA, MNLI, etc.) and found it remains robust, nearly matching a same-size text-only LLM on those tasks. This means users don’t have to trade off text ability when adopting DeepSeek-VL for multimodal tasks – it can still perform pure text summarization or question-answering competitively. Many earlier multimodal models saw drops in these scores, so this is a significant achievement.
- Real-World Performance: Beyond academic benchmarks, the developers conducted human evaluations on real-world tasks and found DeepSeek-VL provides a superior user experience as a vision-language chatbot. It more accurately follows user instructions in practical scenarios compared to other open models. For instance, in an interactive setting where a user shows it a webpage screenshot and asks a series of questions, DeepSeek-VL’s responses were more detailed and correct, whereas other models might miss nuances (like small text or contextual details in the image). This focus on real user scenarios (reinforced by the model’s instruction-tuning dataset built from actual use cases) is reflected in its performance – a critical factor since a model’s usefulness is ultimately measured by end-user satisfaction, not just benchmark numbers.
- Comparison with GPT-4 Vision: GPT-4’s vision-enabled model (often accessed through tools like ChatGPT Vision) is a gold standard for multimodal AI, capable of analyzing images with remarkable accuracy and detail. While GPT-4V is proprietary and highly resourced, DeepSeek-VL competes by being open and specialized. In tasks like simple image description or straightforward Q&A, GPT-4’s larger knowledge might give it an edge, but DeepSeek-VL is not far behind for many queries. On tasks involving domain-specific images or high-res detail (e.g., reading fine print on an image), DeepSeek-VL’s dedicated high-res encoder can shine. It’s reported that a significant gap still exists between most open-source multimodal models and top closed models in complex real-world tasks, but DeepSeek-VL is among the leaders closing that gap. It may not consistently match GPT-4’s accuracy in every scenario, but it provides competitive performance at the same model scale and with the benefit of customizability. For many applications where GPT-4V’s use is limited (due to cost or privacy), DeepSeek-VL offers a viable alternative with surprisingly strong results.
- Comparison with Other Open Models: DeepSeek-VL can be contrasted with open multimodal models like LLaVA, BLIP-2, Flamingo, and MiniGPT-4. LLaVA (which connected LLaMA with a vision encoder) was a pioneer but was limited to modest image resolution and relied heavily on pre-existing vision features; DeepSeek-VL outperforms LLaVA especially on tasks needing detailed vision analysis (tiny text, dense charts) thanks to its architecture. BLIP-2 and similar models (which often use a CLIP image encoder plus an LLM) are efficient and good at image captioning, but they are typically not as adept at interactive QA or complex reasoning – areas where DeepSeek-VL’s integrated training yields better consistency and reasoning over images. Moreover, the introduction of DeepSeek-VL2 with MoE gives it a further edge: models like Flamingo (DeepMind’s earlier multimodal model) were very large (80B+) and resource-intensive; in contrast, DeepSeek-VL2 achieves comparable performance with only ~4.5B active parameters by leveraging experts. This is a new state-of-the-art efficiency in open multimodal modeling. Overall, DeepSeek-VL(1 and 2) sits at the forefront of open vision-language AI, combining lessons from both the vision community and LLM community to deliver high performance in a resource-effective package.
DeepSeek-VL vs. Leading Multimodal AI (GPT-4, Gemini, etc.)
When considering the broader landscape, it’s useful to compare DeepSeek-VL to some well-known multimodal AI systems:
- GPT-4 Vision (OpenAI): GPT-4’s vision capability (often just referred to as GPT-4V) can interpret images and is integrated into ChatGPT for tasks like describing photos or solving visual puzzles. It is exceptionally strong at understanding complex images, thanks to GPT-4’s massive general knowledge and reasoning abilities. However, it’s closed-source and each use comes with cost and usage limits. DeepSeek-VL’s advantages lie in its openness and specialization: while GPT-4V is a generalist, DeepSeek-VL was specifically designed with real-world visual tasks in mind. It was trained on data like web screenshots, charts, and documents that align closely with practical use cases, which means for tasks in those domains it might perform very robustly. For instance, if you ask both models to read a dense scientific PDF page image, GPT-4 might do well, but DeepSeek-VL has actually been tuned on such content and might catch domain-specific details more reliably. Still, GPT-4 has the advantage of scale and might outperform DeepSeek on highly abstract or knowledge-intensive image queries (e.g., interpreting a famous painting in historical context). Many see DeepSeek-VL as bringing GPT-4-like vision-language abilities to the open-source world, allowing anyone to deploy similar capabilities without relying on OpenAI’s API.
- Claude and Other Text-Only Models: It’s worth noting that Anthropic’s Claude 2 and other competitors like Meta’s LLaMA family currently do not natively support images. They are text-only. So in this regard, DeepSeek-VL doesn’t have a direct comparison with Claude because Claude cannot do vision tasks (unless integrated with a separate vision system). Google’s PaLM 2 (basis of Bard) had some image abilities in Bard, but those were limited. Gemini, however, is designed to be multimodal from the ground up. Gemini Ultra can handle text and images (and possibly more modalities) in one model. It’s reportedly extremely powerful – e.g., surpassing GPT-4 in many benchmarks as noted above – and being a Google model, it has vast training resources. DeepSeek-VL vs Gemini is a David vs Goliath scenario in terms of resources: Gemini Ultra likely has tens of billions of parameters (or more) for vision alone, whereas DeepSeek-VL is 7B or MoE 4.5B active. Yet, DeepSeek-VL holds its own by targeting efficiency and specific use cases. Gemini is not open, so developers can’t inspect or fine-tune it; DeepSeek can be adapted to niche domains (say, a specialized medical imaging assistant) by fine-tuning on domain images and text. Also, cost-wise, running DeepSeek-VL on your hardware could be far cheaper than calling an API for Gemini (if it were available externally). In summary, while Gemini and GPT-4 remain at the cutting edge of raw capability, DeepSeek-VL offers a balance of high performance, openness, and practicality. It showcases that an open model can be built to competitive standards in vision-language tasks without needing a trillion-parameter scale.
- Specialized Vision Models: One might also compare DeepSeek-VL to purely vision-focused models like Google’s Vision AI (e.g., Google Vision API for OCR) or DeepMind’s Perceiver, etc. The difference is DeepSeek-VL is a unified model that does both vision and language together. Instead of just giving an OCR text output or classification labels, it can have a conversation about an image. This multimodal conversational ability is something only a few systems (like GPT-4V or some research models) have. So DeepSeek-VL is carving out a niche where it’s not just about detecting or recognizing in images, but truly understanding and discussing visual content in natural language. This makes it far more flexible for users – you can ask follow-up questions about an image, request different forms of output (summary, explanation, analysis), etc., all in one session with the model.
Industry Relevance and Applications
DeepSeek-VL, by virtue of being open-source and high-performing, is poised to impact various industries and domains.
Here are some prominent areas and examples of how it can be applied:
- Robotics and Automation: For robots or drones operating in the real world, a model like DeepSeek-VL can serve as the “eyes and mouth” of the system. For instance, a warehouse robot equipped with a camera could use DeepSeek-VL to read signs or labels on packages and follow spoken-language commands about them (“find the box labeled Fragile and bring it to loading bay 3”). In manufacturing, it could help analyze instrument gauges or control panel screenshots and inform operators if something is out of range. The embodied intelligence capability – understanding complex scenes – is crucial for robots to interact safely and effectively with human environments.
- Customer Service and E-commerce: Businesses can integrate DeepSeek-VL into customer support tools. Customers might upload a photo of a defective product, and an AI assistant could analyze it (“The image shows a cracked screen on model X phone”) and automatically initiate a warranty claim or troubleshooting steps. In e-commerce, a visually-aware chatbot could let users upload an image of an item they want, and the bot can find similar products in the catalog by describing the photo’s content (this blends computer vision and natural conversation).
- Content Moderation and Analysis: Platforms dealing with user-uploaded images (social media, forums) could use DeepSeek-VL to automatically caption or tag images, and importantly, to flag inappropriate content. Because it understands both the visual and textual context, it might catch things like hateful memes (where text in the image is offensive) or misinformation in chart images. Being open, it can be self-hosted for moderation pipelines to maintain privacy.
- Research and Knowledge Extraction: Researchers in fields like history or geology often work with images (photographs of artifacts, satellite images, etc.) and text together. DeepSeek-VL can assist by extracting data from images and linking it with textual info. For example, an archivist could feed a handwritten historical letter image and get a transcription plus context explanation. Or a scientist could ask it to analyze a graph from a paper and summarize the findings. As the model was trained on knowledge-based content including expert knowledge and textbooks, it is better equipped to handle scholarly content than generic models. This makes it a valuable tool for academic and scientific workflows.
- Creative Design and Multimedia: In creative industries, DeepSeek-VL could function as a design assistant. A graphic designer might input a rough sketch or layout image and ask for suggestions or interpretations (“Does this infographic clearly convey the data?”). The model can provide feedback in words, something purely visual tools can’t do. Video editors could use it to analyze video frames (by sampling key frames as images) to generate captions or summaries. Also, because it’s conversational, artists can brainstorm with it about visual ideas (“If I have an image of a night sky with fireworks, what feelings does it evoke? Can you suggest a caption or a short poem about it?”). DeepSeek-VL will interpret the image and respond creatively in text, bridging the gap between visual art and language.
Conclusion
DeepSeek-VL represents a significant leap for open-source multimodal AI.
It brings forth a model that is accessible, versatile, and tuned for real-world visual-linguistic tasks, reducing the dependence on closed models like GPT-4 Vision.
By excelling in areas such as high-resolution image understanding, OCR, and multi-turn reasoning about images, DeepSeek-VL has set a new benchmark for what an open vision-language model can achieve.
The ongoing development (with DeepSeek-VL2’s introduction of MoE) shows the commitment to pushing performance even higher, while still emphasizing efficiency – something highly relevant for companies or researchers who need to deploy these models under resource constraints.
The impact of DeepSeek-VL is far-reaching: it empowers developers to build truly multimodal applications – ones that see and talk – without exorbitant costs or proprietary limitations.
Industries from healthcare to education stand to benefit as AI can now seamlessly analyze visual information and communicate insights.
Moreover, the open-source nature means a community of contributors can audit, improve, and adapt the model, leading to continuous enhancements (for example, fine-tuning it to new domains or improving its safety with community-created filters).
In a world where AI is increasingly expected to interact naturally with us and our environment, models like DeepSeek-VL are indispensable.
They not only demonstrate that open models can keep up with tech giants in innovation.
but also ensure that the capabilities of multimodal AI are widely distributed and not locked behind corporate APIs.
As a result, DeepSeek-VL and its successors are likely to play a key role in the next generation of AI applications – from helpful household robots to intelligent document assistants – making our interaction with technology more intuitive and powerful than ever before.
In essence, DeepSeek-VL is leading the charge for open, advanced vision-language understanding, proving that real-world AI assistants can be built in a way that is inclusive, transparent, and beneficial to all.