Deep-seek.chat is an independent website and is not affiliated with, sponsored by, or endorsed by Hangzhou DeepSeek Artificial Intelligence Co., Ltd.

DeepSeek V3.1: A Next-Generation Hybrid AI Model
DeepSeek V3.1 is an advanced open-source large language model (LLM) that represents a major leap in AI capabilities and scale.
Released in late August 2025, DeepSeek V3.1 builds on its predecessors with cutting-edge features designed for high performance and versatility.
It introduces a hybrid inference design – essentially two modes of reasoning in one model – along with massive model size and context length expansions.
In this comprehensive overview, we’ll explain what DeepSeek V3.1 is, detail its technical specifications, architecture, and training methods, explore its capabilities and use cases, and discuss its role in the broader AI ecosystem.
By the end, you’ll understand why DeepSeek V3.1 is a significant development in the world of AI and how it stands out as a state-of-the-art foundation model.
What is DeepSeek V3.1?
DeepSeek V3.1 is a state-of-the-art large language model released by DeepSeek as the latest iteration of their AI platform.
It’s best known for its hybrid reasoning approach, which allows the model to operate in two distinct modes – “thinking” mode and “non-thinking” mode – within a single unified model.
In practice, this means the model can toggle between a rapid response mode for straightforward queries and a more deliberative reasoning mode for complex tasks that may involve step-by-step problem solving or tool use.
This “one model, two modes” hybrid inference capability is a core innovation of V3.1, aimed at moving toward what the developers call “the agent era” of AI – where AI systems can think, reason, and use tools autonomously as needed.
Under the hood, DeepSeek V3.1 is built on a Mixture-of-Experts (MoE) transformer architecture at an unprecedented scale for open models.
It boasts 671 billion total parameters, of which about 37 billion parameters are activated per token during inference.
(In other words, it uses a sparsely-activated expert model: not every parameter is used for every input, enabling a huge overall model capacity while keeping runtime efficient.) To put this in perspective, most conventional LLMs use far fewer parameters – DeepSeek V3.1’s scale is orders of magnitude larger than typical open-source models available up to 2025.
Yet thanks to its MoE design, advanced training techniques, and optimized inference mechanisms, it remains highly efficient in operation.
Another standout feature is its extremely long context window. DeepSeek V3.1 supports input contexts up to 128,000 tokens in length, allowing it to ingest and work with very large documents or multi-turn conversations without losing track.
This 128K context is far beyond the few thousand tokens context of many standard models, making V3.1 ideal for tasks like analyzing lengthy reports, handling entire books or extensive dialogues in one go, and powering complex multi-step agents that accumulate information over many interactions.
Open-source availability: Importantly, DeepSeek V3.1 follows DeepSeek’s mission of openness – the model’s weights are available to the community (with both the base model and fine-tuned chat model open-sourced).
This means researchers and developers can download and run DeepSeek V3.1 on their own infrastructure or via platforms like Hugging Face, fostering transparency and innovation.
It also offers an API and a web app (DeepSeek Chat) for easy access, making the model broadly accessible as an AI assistant or development platform.
Key Improvements and Features in V3.1
Compared to its previous generation (DeepSeek V3.0) and other variants, V3.1 brings several significant improvements:
- Hybrid Reasoning Modes: A single model can operate in non-thinking mode for direct Q&A and in thinking mode for chain-of-thought reasoning, simply by changing the prompt format. This hybrid approach lets DeepSeek V3.1 both answer quickly when appropriate and tackle complex problems with intermediate reasoning steps when needed – all within one unified system.
- Smarter Tool Use (Agent Capabilities): Through additional post-training optimization, V3.1 is much better at using external tools and performing multi-step “agent” tasks. In thinking mode, it can decide to call tools (like search engines, calculators, code interpreters, etc.) to fetch information or execute commands as part of its response. This makes it a foundation for building AI agents that can interact with external systems, browse the web, run code, or manipulate data based on the model’s reasoning. DeepSeek V3.1’s tool-calling format and agent interfaces have been refined so it can seamlessly integrate tool outputs into its answers, markedly improving performance on complex interactive tasks.
- Higher Reasoning Efficiency: Despite its complex reasoning ability, V3.1 is faster and more efficient in “thinking” mode than earlier DeepSeek reasoning models. In fact, DeepSeek-V3.1-Think can reach answers in less time than the previous DeepSeek-R1 reasoning model without sacrificing quality. The team reports that V3.1’s chain-of-thought responses achieve similar quality to DeepSeek-R1’s outputs, but with a noticeable speed boost. This efficiency gain means users get thoughtful, step-by-step answers faster, which is crucial for an interactive AI assistant experience.
- Massive Scale & Long-Term Memory: With 671B parameters and a 128K token context window, DeepSeek V3.1 can handle tasks that overwhelm other models. It has effectively 10-30x the context length of most mainstream LLMs, enabling it to remember very long conversations or analyze huge texts in one session. This long context is paired with training on extremely large datasets, giving V3.1 a vast knowledge base and the ability to carry out deep reasoning across long documents without losing track of details. For example, it could summarize or answer questions about an entire book or maintain context over hundreds of chat turns – scenarios where normal models would forget earlier parts.
- Open and Accessible: Unlike many cutting-edge models which are proprietary, DeepSeek V3.1 is open. The open-source release of V3.1’s base and fine-tuned weights allows the community to use and even fine-tune the model themselves. This openness is coupled with an easy-to-use API Platform and a consumer-facing DeepSeek Chat app, meaning both developers and end-users can leverage V3.1. The open model fosters research (for instance, you can study its behavior or adapt it to new domains) and helps narrow the performance gap between open models and the best closed models in the industry.
In summary, DeepSeek V3.1 is a powerful, hybrid-mode AI model that merges sheer scale (in parameters and context length) with sophisticated reasoning and tool-using abilities. Next, let’s dive deeper into its technical specifications and how it’s built.
Key Technical Specifications of DeepSeek V3.1
To better understand DeepSeek V3.1, it’s useful to look at its core specifications and features in a structured way. The table below summarizes the key technical specs of the model:
| Specification | DeepSeek V3.1 |
|---|---|
| Model Type | Large Language Model (Transformer) – Mixture-of-Experts (MoE) architecture |
| Total Parameters | 671 billion (total parameters in the MoE model) |
| Active Parameters | ~37 billion per token (parameters actually activated for each inference step) |
| Architecture Features | Multi-head Latent Attention (MLA) mechanism; “DeepSeekMoE” expert layers (custom MoE design); FP8 precision training |
| Training Dataset | 14.8 trillion tokens (pre-training on diverse, high-quality text) |
| Additional Training | +840 billion tokens continued pre-training for 128K context extension; Supervised Fine-Tuning and Reinforcement Learning (RLHF) for alignment |
| Context Window | 128,000 tokens (extremely long context support) |
| Modes of Operation | “Non-Thinking” mode (direct answering) and “Thinking” mode (chain-of-thought reasoning with tool use) |
| Benchmarked Capabilities | Excellent knowledge and reasoning (e.g. ~92% on MMLU academic exam benchmark); Strong coding ability (e.g. competitive programming rating ~2090 in Codeforces tests); Improved multi-step tool-using performance (e.g. significantly higher scores on agent benchmarks like SWE and Terminal benchmark) |
| Open-Source Availability | Yes – Available on Hugging Face (DeepSeek-V3.1-Base and DeepSeek-V3.1 fine-tuned model) under MIT license; also accessible via API and web app. |
| Release Date | August 21, 2025 (announcement of DeepSeek V3.1) |
Table: Key specifications and features of DeepSeek V3.1. As shown, DeepSeek V3.1 combines a massive MoE architecture and long context with specialized training to enable hybrid reasoning modes and top-tier performance across a range of tasks.
Let’s break down some of these technical aspects further:
Architecture and Design
Mixture-of-Experts (MoE) at Unprecedented Scale: DeepSeek V3.1’s architecture is based on a Mixture-of-Experts transformer, meaning the model consists of multiple expert subnetworks (or “experts”) and a gating mechanism that activates only a subset of these experts for each input token.
The model totals 671 billion parameters, but only about 37 billion parameters are used per token inference on average.
This design allows V3.1 to achieve the benefits of an extremely large model (diverse knowledge and capacity spread across many experts) while keeping inference computationally feasible (since not all experts fire for every token).
According to the DeepSeek technical report, this MoE architecture is accompanied by a custom mechanism called DeepSeekMoE, combined with Multi-Head Latent Attention (MLA) to further enhance efficiency.
These techniques (validated in the prior V2 model) help route each query to the right mixture of experts and make sure the model’s enormous capacity is utilized effectively.
Efficiency and Load Balancing: One challenge with MoE models is ensuring that the load is balanced across experts (so all those parameters actually contribute and no single expert becomes a bottleneck).
DeepSeek V3.1 pioneers an auxiliary-loss-free strategy for load balancing – in simpler terms, it managed to train the MoE without needing additional loss terms or tricks to force balanced expert usage.
This likely simplifies training and avoids some downsides of earlier MoE approaches. Additionally, the model uses a multi-token prediction objective during training, meaning it can predict multiple tokens in parallel during each step.
This can improve training efficiency and perhaps inference speed, as the model learns to generate text more fluidly rather than strictly one token at a time. All these innovations make DeepSeek V3.1 a highly efficient model despite its gargantuan size.
In fact, the creators report that the entire DeepSeek V3 training (which V3.1 builds upon) required only about 2.788 million H800 GPU hours, with a remarkably stable training run (no major loss spikes or restarts) – a testament to their engineering of the training process.
128K Context Window Engineering: A headline feature of DeepSeek V3.1 is its 128,000-token context length. Achieving such a long context in a transformer model is non-trivial.
The DeepSeek team employed a two-phase long context extension strategy to extend the context from the base model’s usual limit (likely 4K or 8K tokens) out to 128K.
According to the V3.1 release notes, they first performed a 32K context extension phase of training (feeding longer sequences up to 32k tokens) with a large volume of text, and then a 128K extension phase, for a total of 840 billion additional tokens of training dedicated to expanding context handling
Specifically, the 32K phase was scaled up 10× (630B tokens) and the 128K phase by 3.3× (209B tokens) compared to earlier experiments.
This intensive continued pre-training on long sequences taught the model to retain and utilize information over very long documents.
The result is that DeepSeek V3.1 can maintain coherence and recall over hundreds of pages of text – a feature extremely useful for applications like lengthy document summarization, analyzing transcripts, or powering chatbots that remember the entire conversation history.
It’s worth noting that to make this feasible, memory and compute optimizations were needed; DeepSeek V3.1 was trained using a FP8 (8-bit floating point) data format (specifically the UE8M0 format), which reduces memory usage and speeds up training/inference without significant loss in model fidelity.
This is an emerging trend in training ultra-large models – using lower precision like FP8 can drastically cut the resource requirements.
Prompt Format for Hybrid Modes: The “thinking” vs “non-thinking” modes in DeepSeek V3.1 are implemented via special prompt tokens in the input, rather than separate models.
Essentially, a special <think> token is used to signal the model to engage its chain-of-thought mode.
In practice, when using the model via the API or SDK, developers can prepend certain tokens or format the conversation in a way that either encourages the model to think step-by-step (perhaps generating intermediate reasoning internally or even visibly) or to answer straightforwardly.
The default “chat” mode (non-thinking) uses a closing </think> tag in the system prompt to tell the model it should directly produce an answer.
Conversely, omitting that or using an opening <think> tag triggers the model’s more analytical mode. This clever use of prompt engineering means one model can fluidly switch cognition styles on demand.
Notably, in thinking mode, DeepSeek V3.1 can integrate with an agent framework, where it may output special tokens indicating tool usage (like <|tool_call|> blocks) to perform actions.
The model card documentation provides templates for how to format prompts to utilize tools or code execution steps. All of this is baked into the model’s training – it was fine-tuned to understand these conventions.
In summary, DeepSeek V3.1’s architecture is a blend of massive scale and innovative engineering: a mixture-of-experts transformer with custom attention mechanisms and long-context support, trained with cutting-edge techniques (like FP8 precision and multi-token objectives) to achieve both high performance and practical usability.
Next, we’ll look at how it was trained and what that means for its capabilities.
DeepSeek V3.1 API Pricing

Training Process and Methodology
Training a model as powerful as DeepSeek V3.1 required an enormous amount of data and a carefully staged process:
Pre-training on 14.8T Tokens
The journey began with an extensive pre-training phase. DeepSeek V3 (the base model on which 3.1 is built) was trained on a colossal corpus of 14.8 trillion tokens of text.
This dataset was diverse and high-quality, likely comprising internet text, books, articles, code, and other sources in multiple languages (DeepSeek’s benchmarks suggest the model is multilingual to some extent, as it’s evaluated on both English and Chinese tasks).
The huge scale of training data ensures that the model has absorbed a vast range of knowledge – from factual information and common sense to programming patterns and mathematical formulas.
Such breadth and depth of pre-training is critical for the model’s general knowledge and linguistic fluency.
Mixture-of-Experts Training
During pre-training, the MoE architecture was trained using DeepSeek’s custom approaches (MLA and DeepSeekMoE).
The team introduced an interesting twist by using a “multi-token prediction” objective – rather than strictly predicting one next token at a time, the model was optimized to sometimes predict multiple subsequent tokens in one go. This can make training more efficient and help the model learn longer-range patterns.
They also addressed the typical MoE challenge of expert load balancing without the auxiliary loss trick, as noted earlier, which likely simplified the training dynamics for 671B parameters spread across experts.
Despite the unprecedented scale, the training was reported to be stable and did not suffer catastrophic loss divergences, which is notable (instabilities sometimes occur in ultra-large model training).
Long Context Extension Phases
As highlighted, after the initial base model was trained (with a certain context length, possibly 4K or so), DeepSeek performed continued training to extend the context window.
This was a two-phase process: first extending to 32K tokens context using a 630B token dataset of long sequences, then extending to 128K context with another 209B tokens. These phases likely involved feeding the model extremely long texts (perhaps concatenated books, multi-document collections, or long conversations) so it learns to pay attention over long distances.
The use of position interpolation or specialized position encodings may also have been part of the method (common techniques to enable longer contexts), though specific details aren’t given in the summary.
By the end, the model had effectively learned how to handle inputs as long as 128,000 tokens – making it one of the few models in the world with such a context length in 2025.
Supervised Fine-Tuning (SFT)
After pre-training the base model, DeepSeek V3.1 underwent a supervised fine-tuning stage. In SFT, the model is trained on example prompts and responses (often written by human annotators) to make it follow instructions and behave helpfully in a conversational setting.
This is where the model learns to produce well-structured answers, follow the user’s query intentions, and maintain a polite/helpful style. It’s also during SFT (and later RLHF) that the specific prompt formats for things like the <think> token, tool usage, function calling, etc., would be taught.
The mention of post-training optimization for tool use suggests that some of the fine-tuning data included scenarios where the model should decide to invoke tools (like using a calculator for a math problem, or calling a search API for a knowledge question) – thereby training it to be an effective AI agent.
Reinforcement Learning with Human Feedback (RLHF)
Following SFT, the model likely went through an RLHF stage. In RLHF, human evaluators provide feedback on the model’s responses (ranking them or judging them against each other), and a reinforcement learning algorithm (like proximal policy optimization) is used to further refine the model.
The goal is to align the model’s behavior with human preferences, improving attributes like helpfulness, correctness, and harmlessness. RLHF is a common step in modern large models (it’s how models like ChatGPT are aligned), so DeepSeek V3.1 presumably used it to ensure the model not only knows a lot, but also responds in a user-friendly and safe manner.
As an outcome, V3.1 should generally refuse inappropriate requests and produce respectful, coherent answers, aligning with AI safety and ethical guidelines.
Continuous Improvement for Agents
One noteworthy aspect is that after the main training, the DeepSeek team did additional targeted training to bolster the model’s performance on agent tasks. They refer to this as “post-training boosts tool use and multi-step agent tasks”.
This could mean they fine-tuned the model on dialogues where it had to use tools step-by-step, or on specific benchmarks for agents.
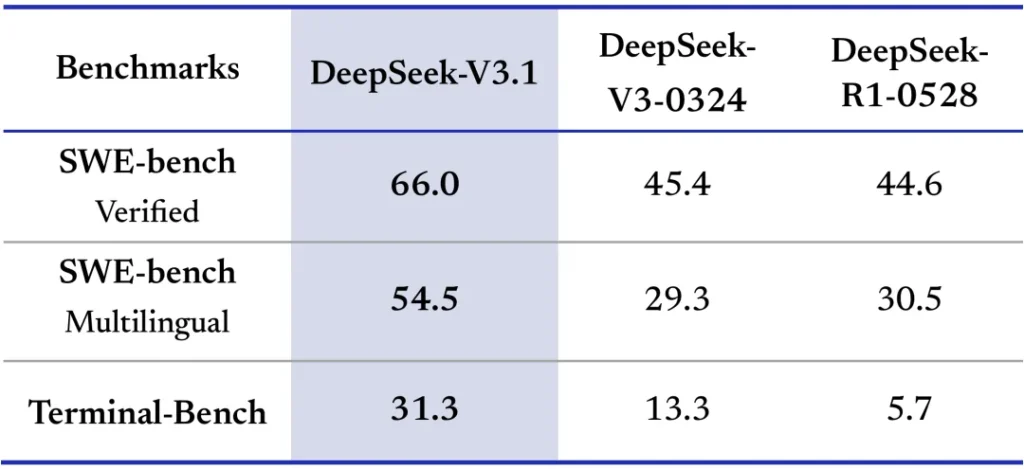
Indeed, the evaluation results show huge jumps in performance on agent-based benchmarks from the previous version to V3.1 – for example, a benchmark called SWE (probably a software engineering agent test) improved from 45.4 to 66.0 score, and Terminal-Bench (a multi-step reasoning task) jumped from 13.3 to 31.3. These gains suggest focused training.
By the end of training, DeepSeek V3.1 became not just a generative text model, but a capable problem-solving agent that can plan actions and handle tools within its responses.
Overall, the training of DeepSeek V3.1 was extensive and meticulous: starting from an enormous general corpus (to give it broad knowledge), then teaching it to handle long contexts, and finally aligning and enhancing it for chat and tool-augmented reasoning. This training pipeline results in a model that is knowledgeable, context-aware, and action-capable. Next, let’s examine what V3.1 can actually do – its capabilities and real-world use cases.
Capabilities and Performance
DeepSeek V3.1 has been tested across a wide array of benchmarks and scenarios, and it demonstrates top-tier performance among large language models.
Here are some of its notable capabilities:
Broad World Knowledge & Reasoning
Thanks to its massive training corpus (14.8T tokens) and scale, V3.1 has encyclopedic knowledge and can answer questions on a variety of topics with high accuracy.
On academic and general knowledge benchmarks like MMLU (Massive Multitask Language Understanding), DeepSeek V3.1 achieves an exact match accuracy around 92% (MMLU-Redux), which is an extremely high score. This indicates expertise across subjects from history and science to mathematics. Its performance is on par with the best models in the world on many such knowledge tests.
The model can follow complex questions, explain its reasoning (especially in thinking mode), and provide well-reasoned answers or solutions. It’s particularly strong at multi-step reasoning problems when allowed to use chain-of-thought – for example, solving math word problems or logical puzzles by working through the solution step by step.
Extended Conversations & Long Inputs
With the 128K context, V3.1 can handle tasks that involve a lot of information. For instance, you could feed an entire research paper or a lengthy legal contract into the model and ask it to summarize or answer questions about it.
It could analyze a book-length text and carry on a discussion referencing details from any part of that text, all within a single session.
This is a game-changer for use cases like literature analysis, long-form report summarization, or supporting a conversation where the user uploads large knowledge bases. The model’s ability to keep track of 128,000 tokens means it essentially has a long-term memory within each session that far exceeds most competitors.
This enables a new level of coherence and depth in conversations – you won’t need to break context or summarize as frequently because the model itself remembers earlier content.
Coding and Software Assistance
DeepSeek V3.1 has demonstrated strong capabilities in computer programming tasks. It’s able to write code in multiple programming languages, debug and fix errors, and even reason about algorithmic challenges.
In coding benchmarks, V3.1 in thinking mode reached a Codeforces (competitive programming) rating of about 2091, which is roughly equivalent to a high-ranking human competitor.
On a benchmark called LiveCode (evaluating writing correct code in one try), it achieved 74.8% pass@1 – an extremely impressive result that outstrips many previous open models and rivals top coding-specific models. This means that given a programming task description, it can produce a correct solution from the get-go nearly 3 out of 4 times.
Additionally, DeepSeek V3.1’s support for tools extends to code execution – it can act as a “code agent” where it writes code, runs it (via an interpreter tool), and then adjusts based on the output.
This opens up use cases like automated debugging or data analysis: you can ask V3.1 to run code to solve a problem and iteratively improve the solution.
Mathematical Problem Solving
The model also excels at advanced math problems when allowed to think stepwise. For example, on challenging math contests for high school level (like the American Invitational Mathematics Examination), DeepSeek V3.1-Think scored above 90% on recent AIME problems, whereas without thinking mode its direct score was much lower.
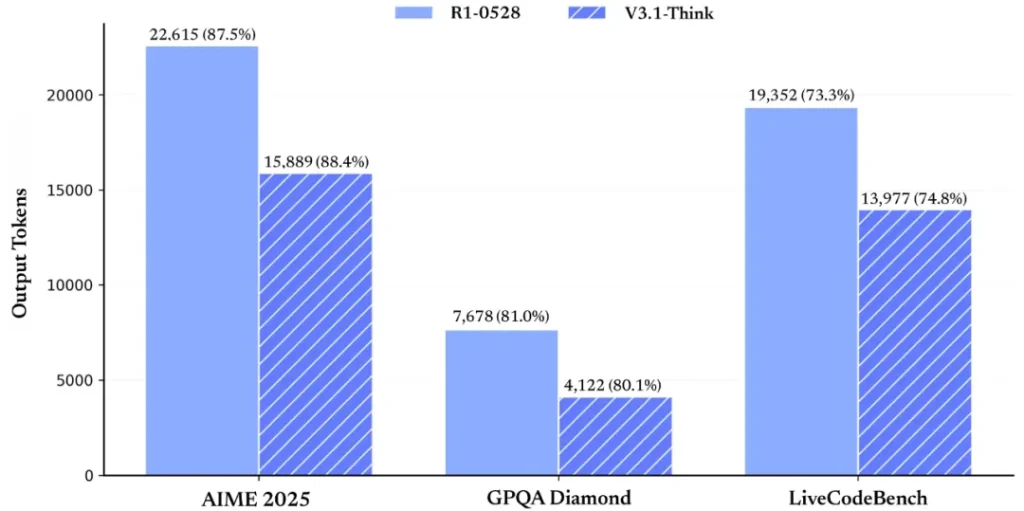
This highlights that the chain-of-thought capability dramatically improves its problem-solving in domains like math, where multiple steps are needed. It can carry out algebraic reasoning, logical deductions, and even some level of calculus or discrete math reasoning.
When needed, the model can call an external calculator or Python tool to compute results (ensuring accuracy for arithmetic or calculus tasks).
The combination of internal reasoning and external tool usage is very powerful here.
Tool Use & Web Browsing:
One of DeepSeek V3.1’s defining features is being “agentic” – it doesn’t just rely on static knowledge; it can actively seek out information.
For questions about current events or very specific data not in its training set, V3.1 (in thinking mode) can use a search tool if integrated.
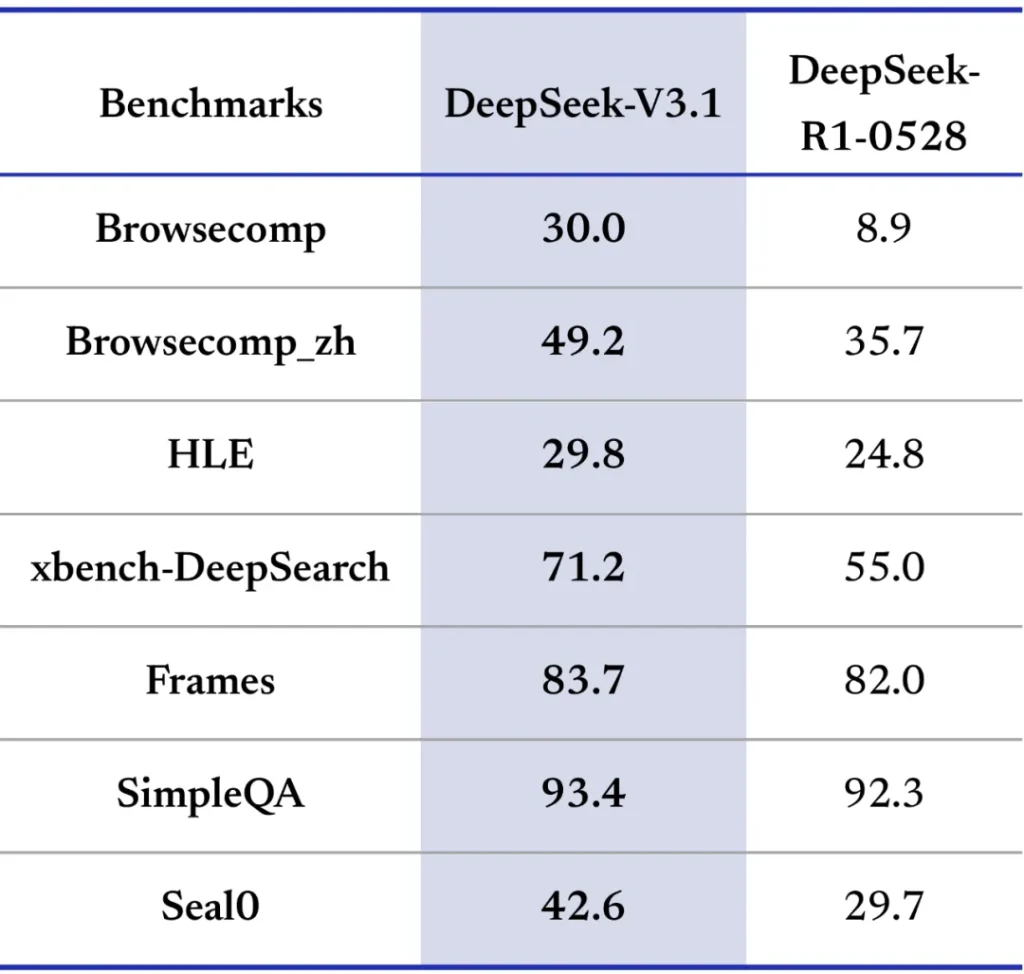
The developers evaluated it with an internal Browse tool and found it far outperforming the previous model: on a browsing comprehension task (BrowseComp), V3.1 scored 30.0, compared to 8.9 by the older model.
This means V3.1 can read web pages and extract answers effectively when hooked up to the internet. Essentially, it can function similarly to an AI agent that does research on the fly, combining its trained knowledge with up-to-date info from the web.
This is extremely useful for tasks like answering latest news questions, verifying facts, or compiling information that wasn’t in its 2025 training data.
Beyond web search, V3.1’s tool use extends to any API you plug in – e.g., database queries, image generation tools (if you ask it to create an image and have such a tool), or other specialized functions.
Creative Generation and Conversation
As a large language model, DeepSeek V3.1 is also adept at creative and conversational tasks. It can generate human-like text for a wide range of prompts: writing stories, drafting emails, composing poetry or lyrics, etc.
Given its training data likely included internet text and literature, it has picked up various styles and can mimic them. Users can have open-ended conversations with DeepSeek Chat (powered by V3.1) and get detailed, contextual responses.
The model tries to adhere to user instructions, stays on topic even in long discussions (thanks to the context length), and can shift tone or format as requested (for example, “Explain this to me as a Shakespearean monologue” or “Provide a bullet-point summary”).
Because of fine-tuning and RLHF, V3.1 is generally aligned to produce helpful and safe outputs, refusing to engage in disallowed content or harmful instructions. This makes it a reliable assistant for everyday queries and creative brainstorming alike.
Performance vs. Other Models
While we can’t name specific competitors, it’s worth noting that DeepSeek V3.1’s benchmark results place it among the absolute top tier of LLMs as of 2025.
The DeepSeek V3 technical report showed that V3 outperformed other open-source models and was comparable to leading closed-source models in many tasks. With V3.1’s further improvements, the gap has narrowed even more.
In essence, V3.1 offers performance in the league of the best proprietary AI systems, but with the benefits of openness and user control.
Few open models come close in scale – most max out at tens of billions of parameters and a fraction of the context – so DeepSeek V3.1 really stands out in the open-model landscape.
Its introduction has been a boon for researchers and companies who prefer or require open-source solutions without compromising on capability.
To give a concrete sense of its prowess: DeepSeek V3.1’s MMLU score (~92) nearly matches the top scores reported by any model (closed or open) on that academic benchmark.
Similarly, its coding benchmark scores are on par with specialized code models and its multi-step reasoning is significantly better than previous generation models.
All this underscores that DeepSeek V3.1 is not just incrementally better – it’s a breakthrough model pushing the frontier of what open AI systems can do.
Intended Use Cases and Applications
DeepSeek V3.1 is a general-purpose AI model, meaning it can be applied to a wide range of use cases. Here we outline some of the most valuable applications and how V3.1’s unique features come into play:
Conversational AI Assistant
DeepSeek V3.1 can serve as an intelligent chatbot or virtual assistant for both businesses and individual users.
Its ability to follow instructions and answer questions in detail makes it well-suited as a customer support agent, a personal assistant, or a tutor. Users can interact with it via natural language to get explanations, advice, or information on-demand.
The non-thinking mode is ideal for quick Q&A and casual dialogue, while the thinking mode allows it to handle complex user requests that may require reasoning or multiple steps.
For example, as a tutoring assistant, V3.1 can walk a student through a difficult physics problem step-by-step, asking sub-questions and checking understanding along the way.
As a personal assistant, it can help plan a multi-stop vacation itinerary (researching hotels, sights, and travel times via tool use) – a complex task beyond simple Q&A.
Content Creation and Writing Aid
With its advanced language generation capabilities, DeepSeek V3.1 is a powerful tool for writers, marketers, and content creators.
It can generate high-quality text in various styles: drafting blog posts, composing marketing copy, writing fiction, or even summarizing transcripts into key points.
The extended context window allows it to work with large amounts of input material – for instance, it could take a long meeting transcript (say 100 pages of text) and produce a concise summary or action points. This is incredibly useful for content synthesis tasks.
Additionally, because the model was fine-tuned with human feedback, it generally produces coherent and contextually appropriate text. Content creators can use V3.1 to overcome writer’s block by generating ideas or entire first drafts that they can then refine.
It can also translate concepts into different tones or formats, e.g., turning technical jargon into layman’s terms or converting an outline into a polished article.
Long Document Analysis
Organizations that deal with large documents – legal contracts, research publications, financial reports – can leverage DeepSeek V3.1 to automate analysis and insight extraction.
Instead of manually reading through hundreds of pages, one could ask V3.1 questions like “Summarize the main obligations of party A in this contract” or “What were the key findings of this 200-page research report?” and get meaningful answers. Because of the 128K token context, the model can take in the entire document at once, maintaining full context of all its sections.
This is a game-changer for industries like law, finance, and academia, where critical information is often buried in voluminous texts. DeepSeek V3.1 can also compare documents – one could feed two lengthy documents and have the model highlight differences or conflicting points.
The hybrid reasoning ensures that if calculations or cross-references are needed (say, summing numbers across pages, or correlating facts from different sections), the model can do that too, potentially using its reasoning mode to outline how it arrives at an answer.
Code Development and DevOps Automation
Software engineers and DevOps professionals can use DeepSeek V3.1 as a coding co-pilot. It can generate code snippets or even entire modules based on natural language descriptions, help debug errors by analyzing error messages and code, and write unit tests.
Given its strong coding benchmark performance, it’s particularly adept at algorithms and can assist in competitive programming prep or technical interviews by explaining solutions. The tool-using capability means it can not only suggest code, but also run it (if integrated with a runtime) and correct itself.
This could be integrated into IDEs or chatbot interfaces where the model writes a piece of code, executes it in a sandbox to verify it works, and then returns the result or fixes any bugs automatically – greatly speeding up the development cycle.
For DevOps, the model could read through log files or configuration files (which can be very long, fitting within 128K tokens) and help diagnose issues or propose configuration changes.
Autonomous Agents and Task Automation
DeepSeek V3.1’s design explicitly points toward autonomous AI agents. With its hybrid modes, it can form the reasoning core of systems like AI assistants that perform tasks on a user’s behalf.
For example, one could integrate V3.1 into an agent that manages email: the model could read a whole email thread (context) and then decide to draft a reply, maybe schedule a meeting via an API, and then send the email – all steps guided by the model’s outputs.
Another scenario is a research agent: given a high-level query, V3.1 could spawn a sequence where it searches the web, reads relevant articles (using its context to absorb them fully), and then synthesizes an answer or report with citations.
Because it can maintain so much information in context and use tools, it’s well-suited to function as the “brain” of complex workflows.
Businesses might use such agents for things like automating customer research (the agent gathers info on competitors or market trends and produces a summary) or even for handling multi-step operations like expense report processing (reading receipts, doing OCR – if combined with a vision tool – then updating a spreadsheet via an API, etc.).
DeepSeek V3.1 provides the general intelligence and reasoning needed for these autonomous systems, reducing the need for human oversight in routine multi-step tasks.
Academic and Scientific Research
Researchers can use DeepSeek V3.1 to assist with literature reviews, data analysis, and hypothesis generation.
Because it can consume massive text inputs, one could feed a collection of research papers or a full textbook to the model and ask nuanced questions about them.
For instance, “What are the differing conclusions between these five studies on climate change?” The model could identify and compare the points, given it has all five papers in context.
It can also help generate hypotheses or research ideas by leveraging its vast learned knowledge – a scientist might have a conversation with the model to brainstorm experiments or to get explanations of complex concepts.
With its math and coding skills, V3.1 can double-check calculations or even simulate simple experiments (via coding tools). This makes it a valuable assistant in scientific discovery and education.
It’s important to note that while DeepSeek V3.1 is extremely capable, users should still apply appropriate verification for critical tasks.
For example, in legal or medical domains, the outputs should be reviewed by professionals. The model sometimes may produce incorrect statements with confidence (a phenomenon known as hallucination in LLMs).
However, the inclusion of tool use mitigates this in many cases, as the model can fetch actual data to back its answers. DeepSeek V3.1’s flexibility means it can be incorporated wherever natural language intelligence is needed, from enterprise solutions to consumer apps.
Its open availability further enables customization – organizations can fine-tune it on their own data (within the allowances of the license) to specialize the model for, say, medical Q&A or specific company knowledge, all while benefiting from the enormous base capabilities.
DeepSeek V3.1 in the AI Ecosystem
DeepSeek V3.1 arrives at a time when the AI ecosystem is rapidly evolving.
Here’s how it fits into and furthers some key trends in large language models:
Closing the Gap Between Open and Closed Models
For a long time, the most powerful AI models (with the highest performance on benchmarks) were proprietary systems from large companies, while open-source models lagged behind in capability. DeepSeek V3.1 is one of the clearest examples of the gap narrowing.
Its performance is comparable to the leading closed-source models of its time, which is remarkable for an openly released model. By open-sourcing a 671B-parameter model, DeepSeek provides the research and developer community a resource that rivals what only a few tech giants have, democratizing access to advanced AI.
This could accelerate innovation as more people can experiment at the cutting edge without needing to train a model from scratch (which would be prohibitively expensive).
In essence, V3.1 pushes the frontier of open AI, making advanced AI more inclusive and transparent.
Scale and “Parameter-Efficient” Design
The industry has recognized that simply making dense models larger (more parameters fully active) yields diminishing returns versus cost.
Techniques like Mixture-of-Experts are a solution to continue scaling capacity without an equivalent blow-up in computation.
DeepSeek V3.1 embodies this “parameter-efficient scaling” – it achieves tremendous scale (hundreds of billions of weights) but is structured in a way that is more efficient than a dense model of the same size.
This approach aligns with trends seen in other research (various MoE models, sparsely gated networks, etc.). V3.1 validates that MoEs can perform at the highest level when done right, and its stable training run serves as a case study that extremely large MoE models are feasible.
We can expect future models to take similar approaches, perhaps increasing the number of experts even more or combining MoE with other architectures.
Long Context and Extended Memory
Another clear trend in the LLM world is the push for larger context windows. From 2023 onward, we saw models going from 2K to 4K to 32K, etc., in context length.
DeepSeek V3.1’s 128K context sets a new standard that few others have publicly matched by 2025. This is indicative of the industry’s aim to integrate more memory and persistence into AI models – effectively, to make them remember and utilize more information in one go.
The ability to handle book-length input opens up new applications and also moves closer to how humans process information (we don’t have such a hard limit on how much context we consider, at least within a single task).
By succeeding with 128K context, DeepSeek demonstrates techniques that others might adopt (like staged training, efficient attention mechanisms, etc.) to reach similar or even greater context lengths.
This contributes to the vision of AI that can continuously learn and converse without forgetting, which is crucial for applications like personal AI assistants that know your entire history or systems that must integrate vast databases of knowledge on the fly.
Agents and Tool Use as the Next Frontier
There’s a growing realization that language models alone are not enough – the next generation of AI systems will be those that can interact with other tools and environments (browsers, databases, robots, etc.). DeepSeek V3.1 explicitly positions itself as a step towards this agentic future.
By training the model to use tools and making “thinking mode” a built-in capability, DeepSeek is aligned with the trend of LLM-based agents (like the various autonomous agent experiments that gained popularity, e.g., in early 2025).
However, many of those experiments used either smaller models or weren’t deeply integrated; V3.1 offers a robust, integrated solution where the model itself knows how and when to use tools because it was taught to do so.
This is likely to inspire further development in the community around standardizing tool APIs for LLMs, improving the reliability of multi-step reasoning, and safety measures (ensuring that agents remain under control and do only what they’re supposed to).
DeepSeek V3.1 can be seen as a platform upon which such agentive AI applications can be built, accelerating the trend of AI not just being a text predictor, but an intelligent actor in a larger system.
Use of FP8 and New Hardware Optimizations
On the technical side, DeepSeek V3.1’s use of FP8 precision in training is part of a broader move to leverage new hardware capabilities.
Modern AI accelerators (GPUs like NVIDIA H100 and others) introduced support for 8-bit floating point operations which allow faster training of large models. By successfully using FP8 (UE8M0 format), DeepSeek likely achieved substantial speedups and memory savings. This showcases to the AI community that one can train huge models more cost-effectively by embracing these innovations.
The result – 2.788M GPU hours for training such a giant model – is actually quite efficient given the scale (for comparison, some smaller dense models have taken similar order of magnitude compute).
This efficiency is crucial for the field because it means even larger or more numerous models can be trained within reasonable budgets, potentially leading to more rapid advancements.
AI Alignment and Safety in Open Models
DeepSeek V3.1 also contributes to the ongoing efforts in aligning AI with human values. It underwent RLHF and presumably has undergone internal safety testing to ensure it follows instructions and avoids harmful output.
By open-sourcing the model, DeepSeek invites the community to scrutinize and improve its safety as well.
This is important because having a high-performing open model allows researchers to study behaviors (good and bad) and develop mitigation techniques in a way that isn’t possible with black-box proprietary models.
DeepSeek’s approach demonstrates that even very large models can be aligned reasonably well (given the model’s helpful behavior in chat and agent tasks).
It also highlights the importance of continued research on alignment – as models become more powerful and agentic, ensuring they behave as intended is paramount. V3.1’s design of separate modes might even be seen as a safety feature: by default, the non-thinking mode doesn’t reveal chain-of-thought, which could contain raw or unfiltered reasoning, whereas thinking mode might be used in controlled contexts.
Such nuances reflect an ecosystem-wide conversation about how to safely deploy models that can reason and act.
In essence, DeepSeek V3.1 is not just an isolated product; it’s a significant player in the LLM field that embodies where the industry is headed: massive, efficient models with long memory and tool integration, made widely available.
Its release has likely spurred competitive responses and collaborations, all of which drive AI technology forward.
For AI enthusiasts and professionals, V3.1 is a model to watch and learn from – whether one is interested in technical architecture, practical applications, or the ethical/societal implications of powerful AI.
Conclusion and Future Outlook
DeepSeek V3.1 represents a milestone in AI development – merging an unprecedented scale of knowledge with adaptability and interactive reasoning.
It provides developers and organizations a versatile AI engine that can power everything from simple chatbots to complex autonomous agents.
By excelling in technical benchmarks and real-world tasks alike, it has set a new bar for what open models can achieve, proving that openness and top performance need not be mutually exclusive.
For users and businesses, DeepSeek V3.1 offers immediate value: it can enhance customer service with more intelligent chatbots, boost productivity by automating complicated workflows, aid in scientific research by digesting huge information volumes, and spark creativity with its generative prowess.
Early adopters integrating V3.1 into their products or research are tapping into one of the most advanced AI brains available.
Looking forward, DeepSeek has hinted at even more ambitious goals. The introduction of V3.1 was described as “just the beginning” and teased future developments like multimodal support (which would allow the model to handle images, audio, or other data types in addition to text).
This suggests that a DeepSeek V4 or related models might integrate vision or other modalities, making the AI even more powerful and context-aware.
We can also anticipate continued improvements in efficiency and alignment – perhaps even longer contexts, more fine-grained control over the model’s reasoning processes, and stronger safeguards.
In the broader AI landscape, the success of DeepSeek V3.1 will likely encourage more collaboration and sharing.
As more organizations see the benefits of large open models, we might witness a growing ecosystem where models like V3.1 serve as foundations for specialized derivatives (for example, a medical version fine-tuned on healthcare data, or a legal assistant fine-tuned on statutes and case law).
DeepSeek V3.1’s MIT license and community access means it could become a base for many such projects, much like earlier open models became the bases for countless fine-tunes.
In conclusion, DeepSeek V3.1 is a trailblazing large language model that combines scale, smarts, and openness.
It brings us closer to AI that can truly understand, reason, and assist across virtually any domain.
Whether you’re an AI researcher, a developer, or an end user, V3.1 is a development worth paying attention to – it’s paving the way for the next generation of AI systems that are more capable, helpful, and integrated into our everyday lives.
Sources: The information in this article is based on official DeepSeek releases and technical documentation, including the DeepSeek-V3 technical report and the DeepSeek V3.1 model card and release notes, as well as performance benchmarks reported by DeepSeek.
These sources attest to the architecture, training methodology, and capabilities described above.
DeepSeek V3.1’s open-source model is available for further review and experimentation on platforms like Hugging Face, underscoring the transparency and community-driven spirit behind this model.
Its advent marks an exciting step forward for AI practitioners worldwide, blending cutting-edge research with practical, real-world usability.