Deep-seek.chat is an independent website and is not affiliated with, sponsored by, or endorsed by Hangzhou DeepSeek Artificial Intelligence Co., Ltd.

DeepSeek Coder: The Open-Source AI Code Assistant Revolutionizing Programming
AI-powered coding assistants have transformed software development, accelerating coding tasks and reducing routine grunt work.
Tools like GitHub Copilot and Amazon CodeWhisperer have become popular by suggesting code in real-time.
Now, DeepSeek Coder has emerged as a powerful open-source alternative that lets developers harness cutting-edge AI code generation without the constraints of closed platforms.
Developed by DeepSeek AI, DeepSeek Coder is a series of large language models (LLMs) specialized for programming – essentially an AI pair programmer you can run on your own terms.
It boasts competitive (even state-of-the-art) performance in code benchmarks and supports a wide range of programming languages.
In this article, we’ll explore what DeepSeek Coder is, how it works under the hood, its key features and practical use cases, and how it stacks up against other coding assistants like Copilot and CodeWhisperer.
If you’re a developer, computer science student, or tech company looking into AI coding tools, read on to see how DeepSeek Coder might fit into your workflow.
What is DeepSeek Coder?

DeepSeek Coder is an open-source AI model series designed to write and understand code. At its core, it’s a large language model trained specifically on programming-related data.
DeepSeek Coder was introduced in early 2024 as a range of code-focused LLMs with sizes from about 1.3 billion to 33 billion parameters.
Unlike many proprietary coding AIs, it’s developed openly by the DeepSeek AI research team and released with a permissive license that allows free use for both research and commercial projects.
In other words, anyone can use and even fine-tune it without worrying about licensing fees or restrictions – a significant advantage for companies and open-source developers alike.
Despite being open-source, DeepSeek Coder doesn’t skimp on firepower. Each model in the series was trained from scratch on an immense corpus of code and natural language – 2 trillion tokens in total – drawn from sources like GitHub repositories, programming Q&A (e.g. StackExchange), and more.
About 87% of the training data is source code (spanning dozens of languages), with 10% English technical content (like docs and code comments) and a small 3% portion of general Chinese text.
This rich dataset gives the model a broad knowledge of programming concepts and libraries.
The initial DeepSeek Coder models support over 80 programming languages out of the box – from mainstream ones like Python, JavaScript, and C++, to more niche languages – enabling it to generate or understand code in a very diverse set of environments.
Another standout feature is its ability to handle long coding contexts. The base models were trained with a context window of up to 16,000 tokens (roughly equivalent to reading 300+ lines of code or more at once).
This is much larger than the context length of older code models (for comparison, OpenAI’s Codex and early Copilot versions handled around 4K tokens).
A long context means DeepSeek Coder can consider entire code files or even multiple files together when generating code or providing suggestions, which is crucial for understanding project-level code structure.
In fact, it was specifically trained on “repository-level” code, meaning it learned to read and generate code in the context of large, multi-file projects rather than isolated snippets.
This training approach helps it produce more coherent and correct code completions that take into account cross-file dependencies – a common scenario in real software projects.
DeepSeek Coder’s tagline is “Let the Code Write Itself,” and its capabilities reflect that vision.
Given a natural language prompt or a partial piece of code, it can generate code of varying complexity in the desired language, fill in missing sections of a program, or even explain and debug existing code (Source).
For example, a developer could ask DeepSeek Coder to “generate a Python function to sort a list of dictionaries by a given key,” and it will produce a plausible implementation.
Or you might feed it a code snippet with a bug and ask, “What’s wrong with this code?” – DeepSeek Coder can highlight the issue and suggest a fix. These sorts of tasks make it a versatile AI assistant for programmers.
It’s worth noting that DeepSeek Coder is part of a larger family of AI models from DeepSeek AI.
The team has built general-purpose LLMs (the DeepSeek LLM series) and domain-specific ones like DeepSeek Math (for mathematical reasoning) and DeepSeek VL (vision-and-language). DeepSeek Coder is their solution for the software development domain.
The first generation (let’s call it DeepSeek Coder V1) was followed up in late 2024 by DeepSeek-Coder V2, an even more powerful iteration.
We’ll discuss V2’s improvements later on, but in brief: the second version scales up model size dramatically using a Mixture-of-Experts architecture and extends the context window to an astounding 128K tokens, enabling it to handle entire codebases in context.
DeepSeek-Coder V2’s largest model has 236 billion parameters (though through MoE techniques only a fraction are active per query)
With V2, the model’s performance is said to reach GPT-4 level on many code tasks – essentially “breaking the barrier of closed-source models” as the authors put it.
In summary, DeepSeek Coder represents a cutting-edge, open platform for AI coding assistance, continuously improving and closing the gap with top proprietary systems.
How Does DeepSeek Coder Work?
Under the hood, DeepSeek Coder works like other large language models, but with special optimizations for coding.
The model architecture is a decoder-only Transformer (similar to GPT-style models) that has been tailored to generate code and handle programming syntax.
According to the technical report, the DeepSeek Coder models use the same underlying architecture as the general DeepSeek LLM, incorporating techniques like Rotary Position Embeddings (RoPE) to effectively handle long sequences of text (i.e., long code files).
By adjusting RoPE scaling, the developers extended the model’s context window substantially – in theory up to 64K tokens for the first-gen models, though they found reliable performance up to 16K in practice.
This means the model can pay attention to very long inputs without losing track of earlier code as quickly, which is vital for tasks like understanding an entire function or module to generate relevant completions.
A key training technique used is Fill-in-the-Middle (FIM) learning. Unlike standard language models that generate text only after a given prompt, FIM training involves giving the model a prefix and a suffix of code and training it to fill the gap in between.
DeepSeek Coder was trained with a 50% probability of such infill tasks. This skill makes it particularly adept at inserting code into an existing codebase – for instance, implementing a missing function in a partially written file, or adding a code block in the middle of a script where some functionality is needed.
In practice, this translates to powerful code completion and refactoring abilities: the model doesn’t just continue code from the end, but can understand context around a blank and generate the missing piece in between.
This is incredibly useful for real-world development, where you often need to modify or add to existing code rather than always writing from scratch.
DeepSeek Coder models were trained from scratch on massive data, but the team also leveraged a smart data preprocessing pipeline to maximize quality.
They applied rigorous deduplication to avoid training on duplicate or boilerplate code, filtered out low-quality code (e.g. incomplete or syntactically incorrect files), and even organized training examples at the repository level.
One interesting detail: they parsed dependencies between files in the same repo and concatenated related files into one training sequence
This way, the model learns patterns of how multiple files in a project reference each other (like import relationships or function calls across files).
Essentially, DeepSeek Coder was taught to “read” entire projects, not just single files, which likely contributes to its strong performance on multi-file completion benchmarks and understanding context across a codebase.
Beyond pre-training, the team produced an instruction-following variant called DeepSeek-Coder-Instruct.
This is analogous to how OpenAI’s base models can be fine-tuned into instruction-following ones (like GPT-3.5 vs ChatGPT).
DeepSeek-Coder-Instruct was obtained by fine-tuning the base model on around 2 billion tokens of high-quality instruction-answer pairs.
These instructions included helpful coding queries and their solutions, formatted in a dialog style (using a special <|EOT|> token to separate turns).
The result is that the Instruct model is much better at understanding human prompts and responding in a conversational, helpful manner – crucial for a good user experience when you ask the AI a question or give it a task.
In fact, this fine-tuning is what allows DeepSeek Coder to function as an interactive coding assistant (you can prompt it with, say, “Optimize this function for speed” or “Explain what this regex does” and get a useful answer).
The developers noted that this instruction-tuning greatly improved zero-shot task performance.
Notably, the DeepSeek-Coder-Instruct-33B model (33B parameters, instruction-tuned) was found to outperform OpenAI’s GPT-3.5 Turbo on several coding benchmarks – a strong validation of its capability as a helpful assistant, since GPT-3.5 Turbo underpins many commercial code assistants.
DeepSeek-Coder V2: Mixture-of-Experts and More
The architecture of DeepSeek-Coder V2 took a leap by adopting a Mixture-of-Experts (MoE) design.
In an MoE model, the network is divided into many “experts” (sub-models specialized in different tasks or data domains), and a gating mechanism decides which subset of experts to use for each input.
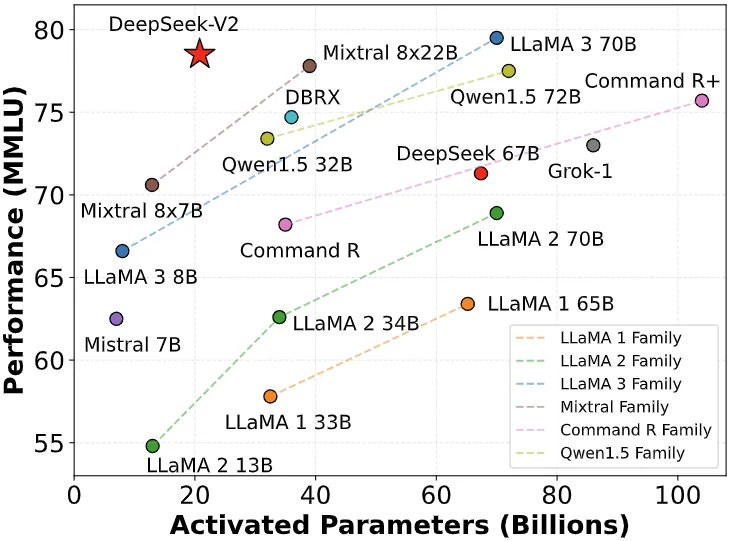
The V2 models come in two scales: a “Lite” with 16 billion total parameters (but only ~2.4B active parameters per token prediction), and a full-size with 236 billion total (21B active).
The MoE approach means that although the total parameter count is huge, any given query only activates a fraction of them, keeping inference tractable.
This allowed DeepSeek-AI to train extremely large models without the full runtime cost of a 236B dense model.
The payoff is evident in performance: DeepSeek-Coder-V2 achieves results comparable to or even surpassing GPT-4 (Turbo) and other top-tier models on code-specific tasks.
In the team’s evaluations, the 236B V2 model hit about 90.2% pass@1 on the HumanEval Python benchmark, which is on par with GPT-4’s performance on that test (and well above older code models).
It also demonstrated strong mathematical reasoning capabilities, outperforming GPT-3.5 and even beating GPT-4 on some math-oriented coding challenges.
Crucially, V2 expanded the supported programming languages from 80+ to 338 languages .
This is a massive coverage – likely including nearly every programming, scripting, or query language one can think of (the supported list ranges from mainstream languages to esoteric ones).
For developers working with less common languages or domain-specific languages, this broad support is a big plus.
And as mentioned, V2’s context window stretched up to 128K tokens. To put that in perspective, 128K tokens might be around 100,000 words – effectively, you could give the model an entire code repository or a very large codebase as input.
This ultra-long context opens possibilities like “repository-level code completion,” where the model can consider the content of many files when generating code in one file.
It’s an impressive technical feat (made possible by efficient attention mechanisms and the MoE scaling).
From a user perspective, the details of architecture (Transformer vs MoE, etc.) don’t require intervention – you interact with DeepSeek Coder through prompts as usual.
But these design choices manifest as tangible benefits: the model can handle larger inputs, more languages, and produce smarter outputs thanks to the way it’s built and trained.
Key Features and Capabilities
Let’s summarize the standout features of DeepSeek Coder and what capabilities it brings to developers:
- 🚀 Open Source & Permissive License: DeepSeek Coder is fully open-source, released under a permissive license that allows free use, modification, and integration even in commercial products. This is a game-changer for companies that are wary of sending code to third-party APIs or for developers who want to fine-tune the model on proprietary code – you have full control over the model.
- 🤖 Advanced Code Generation & Completion: The model excels at generating code from natural language prompts or partial code. It can suggest whole functions or classes given a description, complete your code as you write (like an IDE autocompletion on steroids), or fill in missing code in the middle of a file thanks to its fill-in-the-middle training. It’s not limited to boilerplate – it tries to produce logically correct and even optimized code based on context.
- 🛠 Code Understanding, Debugging, and Explanation: DeepSeek Coder isn’t just a code writer; it’s also a code reader. You can ask it to explain a piece of code in plain English (useful for learning or documenting purposes) or to find bugs/improve the code. Because it was trained on Q&A and forum data as well, it has some capacity to know common pitfalls and idioms. For instance, you might feed it a snippet and ask “Is there a bug in this code?” and it can point out logical errors or suggest edge cases. This makes it a potential debugging assistant or even a reviewer for your code.
- 🌐 Multilingual Support: One of the strong points is the breadth of programming languages understood. DeepSeek Coder V1 covered 80+ programming languages, and V2 expanded this to 300+. This includes not just languages like Python, Java, C#, JavaScript/TypeScript, C/C++, but also things like HTML/CSS, SQL, Rust, Go, PHP, Swift, Kotlin, Shell scripting, and many more – even niche languages or older ones (Fortran? likely yes). This wide coverage is much broader than what most other coding assistants explicitly support. It means whatever your stack, DeepSeek likely has seen that language. It can even handle multiple languages in one prompt (for example, generating both front-end and back-end code, or interacting with SQL and a host language together).
- 📏 Long Context Window (16K–128K tokens): DeepSeek Coder can take into account very large code contexts while generating output. In practical terms, you could paste an entire file (or multiple files) into the prompt, ask a question about it, and the model can refer to any part of that code in its answer. This is extremely useful for understanding or modifying codebases. By contrast, many current AI code tools have smaller context limits (for example, standard GitHub Copilot requests might only use a few hundred lines of surrounding code). DeepSeek’s long context shines in use cases like “complete the following function based on these other module files” or “insert a new feature in this 1000-line file without breaking existing logic.” The model was explicitly trained to handle repository-scale inputs, so it performs well in these scenarios.
- 💡 State-of-the-Art Performance: Thanks to its massive training and tuning, DeepSeek Coder ranks at the top of many coding benchmarks among open models. The 33B model significantly outperformed other open-source code models like CodeLLaMA-34B on benchmarks such as HumanEval (Python and multi-language), MBPP (Manytask Programming Benchmark), and DS-1000 (a diverse Data Science code benchmark). In fact, the 7B parameter DeepSeek model was about on par with a 34B CodeLLaMA, showing how well the training was done. After instruction tuning, the largest model even surpassed OpenAI’s Codex/GPT-3.5 on code generation tests. With V2, the performance jumped even higher – reaching near GPT-4 accuracy in code tasks and beating other closed models like Anthropic’s Claude 3 and Google’s Gemini (according to the DeepSeek team’s evaluations). For users, this means you’re getting industry-leading code suggestions and solutions, not a secondary-tier open model.
- 🧠 Mixture-of-Experts Architecture (V2): While a bit technical, it’s worth noting that the V2 model uses an MoE architecture. This innovation allows expert specialization within the model – some experts might be better at certain languages or tasks. It helps the model handle a wide array of problems efficiently. The practical upshot is better quality and faster inference for its size. MoE also means DeepSeek Coder can continue scaling up (adding more experts) without needing a single gigantic model, suggesting a path to even more powerful versions in the future.
- 🔧 Customizability and Fine-Tuning: Because the model and code are open, advanced users can fine-tune DeepSeek Coder on their own data or for specific tasks. The authors provide scripts to fine-tune the models on downstream tasks, so you could, for example, teach it the patterns of your proprietary codebase or ask it to specialize in a framework. This is something closed services don’t allow (you can’t fine-tune Copilot on your data). Fine-tuning can further improve performance in specific domains.
In essence, DeepSeek Coder offers a feature set comparable to (or beyond) the best commercial coding assistants: code generation, multilingual support, long context, high accuracy, and a flexible open deployment.
Next, let’s look at how these capabilities translate into real-world use cases for developers and teams.
Practical Use Cases of DeepSeek Coder
How can developers, students, or tech companies actually use DeepSeek Coder in practice? Here are some of the most compelling use cases and scenarios where this AI coder shines:
- Intelligent Code Autocomplete in IDEs: Just like GitHub Copilot can suggest the next line or whole function as you type, DeepSeek Coder can be used to power smart autocompletion in your development environment. Although DeepSeek doesn’t (yet) have an official IDE plugin, developers can integrate it via its API or open-source plugins. For instance, one could connect a local DeepSeek model to VS Code or Neovim to get suggestions as you write code. Given its knowledge of various languages and libraries, it can complete statements or even anticipate entire blocks of code (loops, API calls, etc.) based on the context. This speeds up coding by reducing boilerplate work – you type a function signature or a comment describing the logic, and DeepSeek Coder can suggest the implementation.
- Natural Language to Code Generation: DeepSeek Coder allows you to write a prompt in plain English (or another human language) and get functioning code in return. This is incredibly useful for quickly prototyping or getting the skeleton of a solution. For example, a data scientist could prompt: “Read a CSV file of sales data into a Pandas DataFrame and calculate the top 5 products by total revenue” – and DeepSeek Coder can produce a Python snippet using
pandasto do exactly that. This lowers the barrier to use new APIs or languages, since the AI can generate correct usage patterns. It’s also a great learning tool: a student can ask for code examples or templates (e.g., “Show a basic React component with a form and state hooks”) and learn from the outputs. - Code Explanation and Documentation: For educators or developers trying to understand unfamiliar code, DeepSeek Coder can serve as an on-demand explainer. You can paste a block of code and ask “What does this code do?” or “Explain this function line by line.” The model will produce a human-readable explanation, essentially acting like a tutor. This is valuable for onboarding new team members to a large codebase or for students debugging an assignment. The instruct version of the model was specifically fine-tuned on QA-style interactions, making it quite adept at these explanatory tasks. It can also generate docstrings or comments for code – useful for improving documentation without manually writing out descriptions for every function.
- Debugging Assistance: Debugging can be accelerated by AI pair programmers. With DeepSeek Coder, one can input an error message or a faulty code snippet and ask for help. For example: “Why is the below function returning null for input X? (with code attached)”. The model can analyze the code, possibly identify logical errors or misunderstandings, and suggest a fix. It might catch things like “You forgot to handle the case when the list is empty, causing an index error” or “The variable
useris not defined in this scope”. While it won’t always pinpoint the bug, having a fresh AI perspective often surfaces issues faster. Some early users have noted that models like this can even propose unit tests to reproduce a bug or verify a fix, acting almost like a rubber-duck debugger that actually talks back with solutions. - Code Refactoring and Optimization: Suppose you have a working piece of code but it’s poorly written or inefficient. You could prompt DeepSeek Coder with, “Refactor the following code to be more readable and Pythonic” or “Optimize this function for speed and explain the changes.” The model can rewrite the code in a cleaner way or using better algorithms, and explain its rationale. Thanks to training on good coding practices from forums and documentation, it has awareness of idiomatic patterns. It might, for instance, replace a triple nested loop with a more efficient approach or apply a known refactoring pattern. This assists developers in improving code quality and learning better techniques.
- Multi-File or Large Project Assistance: Because of the long context, DeepSeek Coder can tackle tasks that involve understanding relationships between files. For example, you could literally paste multiple files (or their relevant parts) into a single prompt and ask the model to implement a new feature that affects all of them. Or ask it questions like, “In this repository, where is the database connection established?” and it could scan through the context to find the relevant code. Another example: providing the model with your
models.py,views.py, andurls.pyfrom a Django project and asking it to generate a new view and route for a certain functionality – it can do so in a way that integrates with existing code, because it “sees” the broader context. This project-level awareness is something even Copilot struggles with due to context limits, making DeepSeek uniquely powerful for large-scale codebase navigation. - Automation in No-Code/Low-Code Platforms: Interestingly, DeepSeek Coder has been integrated into at least one low-code platform (Latenode) to automate code generation within workflows. In such scenarios, business users can describe a logic and the AI node generates the code to execute it. This hints at a broader use case: bridging the gap between non-programmers and code by using natural language. Companies could leverage the model to let users customize software behavior by simply describing it, with the AI producing the necessary code under the hood.
- Education and Skill Development: For programming students, DeepSeek Coder can act as a mentor. It can provide hints or even complete solutions to programming problems, which a student can then study (preferably after attempting themselves!). Because it supports many languages, it’s like having a tutor for any language you’re learning – e.g., “How do I implement quicksort in Haskell?” or “Show an example of a REST API server in Go.” Students can also ask why a piece of code is written a certain way and get an explanation. Of course, as with any AI, students should use it to learn, not just cheat on assignments – but the tool can significantly aid in understanding and exploring programming concepts at one’s own pace.
- Enterprise Use – Secure, Private Coding Assistant: Companies often love what Copilot can do but are wary of sending proprietary code to external services for suggestions. DeepSeek Coder offers a solution: run your own AI coding assistant internally. Since the model can be self-hosted (with sufficient hardware) or accessed via a private API, companies can keep their code and queries in-house, alleviating privacy and compliance concerns. Developers in a company could use DeepSeek Coder on confidential codebases (something that’s a strict no-go with public AI APIs). Additionally, firms can fine-tune the model on their internal code repositories and style guides, so it becomes specialized in their stack and conventions – something truly unique that a one-size-fits-all service cannot provide.
These use cases illustrate that DeepSeek Coder isn’t just a research demo; it’s a practical tool that can slot into many stages of development.
Whether you are writing new code, reading old code, fixing bugs, or learning, an AI assistant like this can save time and enhance productivity.
Of course, as with all AI-generated code, users should review and test everything – the model can make mistakes (or even produce insecure code) if not guided properly.
It’s a helpful co-pilot, not an infallible autopilot. Next, let’s examine how DeepSeek Coder actually performs and how it compares with other major coding assistants on the market.
Performance and Benchmarks
To understand DeepSeek Coder’s capabilities, it’s useful to look at how it performs on standard coding benchmarks and tasks.
The creators of DeepSeek Coder evaluated their models on several well-known coding challenges, and the results are impressive.
One primary benchmark is HumanEval, a test from OpenAI that measures a model’s ability to generate correct solutions to coding problems (originally in Python).
Scoring on HumanEval is usually reported as “pass@1”, meaning the percentage of problems solved correctly by the model on the first attempt.
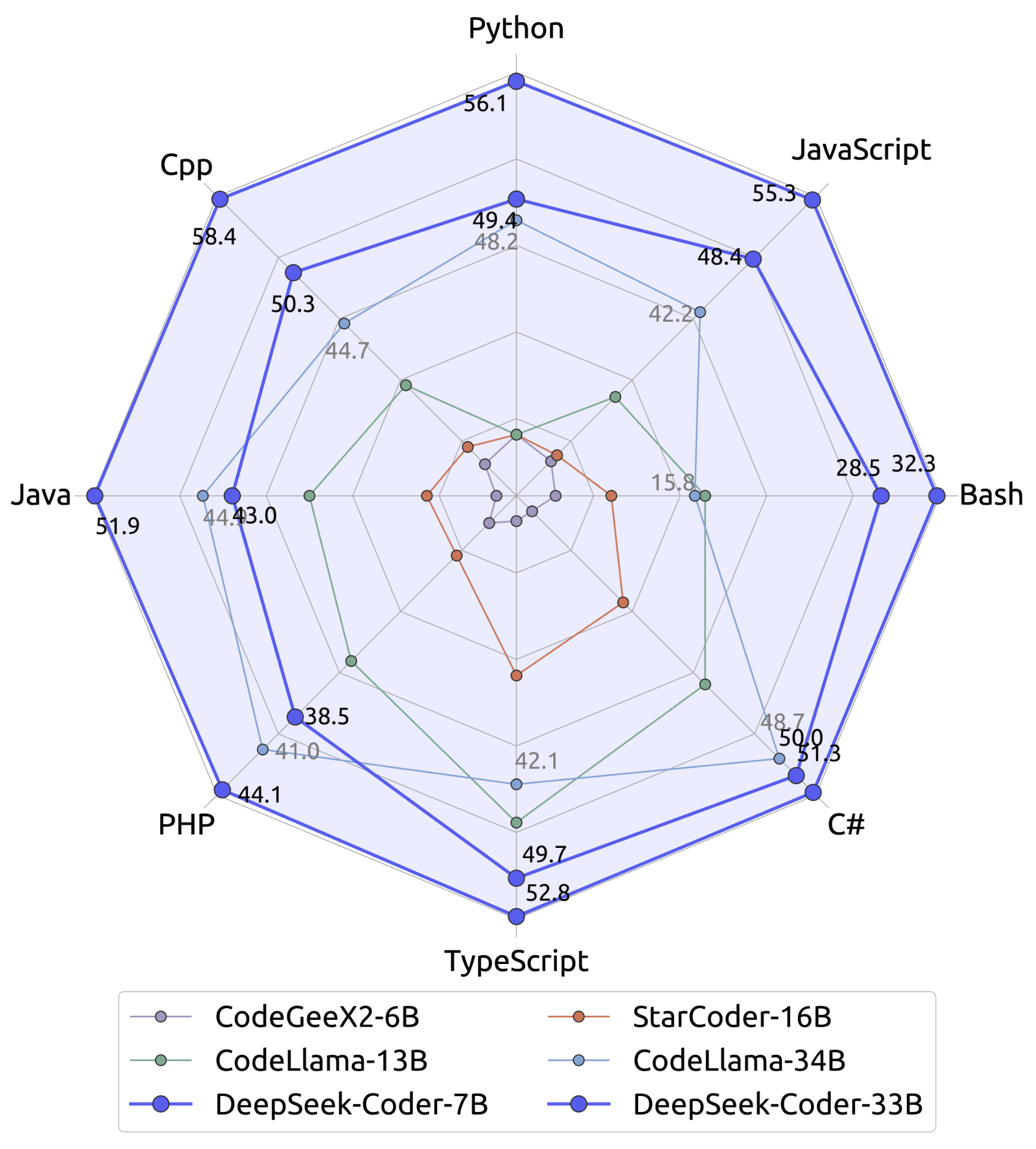
The largest DeepSeek Coder base model (33B) achieves state-of-the-art results among open models – significantly outperforming Meta’s CodeLlama-34B by margins of 7–11% on various tracks.
Specifically, DeepSeek-Coder-33B led CodeLlama-34B by ~7.9% on HumanEval Python and ~9.3% on a multilingual HumanEval variant (which includes problems translated into other languages).
Perhaps more astonishing, the much smaller DeepSeek-Coder 7B model was able to reach parity with the 34B CodeLlama on these evaluations, demonstrating the efficiency of the DeepSeek training approach.
Another benchmark, MBPP (Mostly Basic Python Problems), tests understanding of simple coding tasks. Again, DeepSeek Coder showed strong results, outperforming other open models by double-digit margins.
The DS-1000 benchmark, a set of 1000 real-world data science coding tasks, was also used – here DeepSeek’s model outscored others, indicating an ability to handle practical code that involves libraries and data manipulation.
These open-model comparisons establish DeepSeek Coder as the leading open-source code LLM (at least as of its release timeframe in 2024).
What about comparing to closed-source models? The team did that too. The instruction-tuned 33B model was found to slightly surpass OpenAI’s GPT-3.5 Turbo on HumanEval (which is noteworthy, as GPT-3.5 was the engine behind the initial version of Copilot).
On another benchmark (MBPP), it performed roughly on par with GPT-3.5.
In other words, DeepSeek-Coder-Instruct 33B is in the same league as OpenAI’s Codex/GPT-3.5 in coding ability – a huge milestone for open source.
The researchers also noted that their model series even surpassed Codex (the original model powering Copilot) on some tasks, and generally reduced the gap between open and closed AI performance.
With DeepSeek-Coder V2, the bar was raised higher. In standard evaluations reported, the 236B (MoE) V2 model essentially matched or beat GPT-4 Turbo (the 2024 edition of GPT-4 accessible via API) on multiple coding and math-focused benchmarks.
For example, on HumanEval the DeepSeek-Coder-V2 achieved about 90.2% pass@1, which is in the territory of GPT-4’s reported performance (high 80s to low 90s% depending on version)
It also notched an 76.2% on MBPP+ (an extended version of MBPP), higher than what GPT-4 Turbo scored.
In a benchmark called LiveCode (which assesses code generation in live programming scenarios), DeepSeek V2 came second only to GPT-4, and tied GPT-4 on a math-heavy coding test.
Furthermore, DeepSeek-Coder-V2 outperformed Claude 3 (Anthropic’s model) and Gemini 1.5 Pro (a model from Google’s DeepMind, presumably) in these tests.
While benchmarks aren’t everything, these numbers strongly suggest that DeepSeek Coder V2 is currently the most powerful open-source coding model and is competitive with the best closed models available.
It’s also worth noting multilingual code performance. Since DeepSeek Coder supports a broad set of languages, it was evaluated on a Multilingual HumanEval (problems translated into languages like C++, Java, JavaScript, etc.).
The model performed well, indicating it can write correct code in languages beyond Python. This sets it apart because many code LLMs mainly focus on Python.
For companies or projects using Java, C#, or other languages, having an AI that’s actually been trained on those is crucial – DeepSeek’s training mix (87% code from many languages) gives it that edge.
In more realistic coding challenges, like the DS-1000 (1000 real-world coding tasks) and a custom LeetCode Contest benchmark, DeepSeek Coder again showed strong problem-solving ability.
The LeetCode Contest benchmark, for instance, tests competition-level algorithm challenges; DeepSeek’s success there hints that it can tackle complex algorithmic coding, not just simple scripts.
To temper the enthusiasm: these results are on benchmarks with well-defined metrics. In everyday use, the “feel” of the model’s help will depend on how you prompt it and what IDE integration you use.
It may not always write perfect code (no model does – even GPT-4 can produce errors or require multiple attempts).
But the benchmark dominance tells us that if used properly, DeepSeek Coder can achieve solutions that are at least as good as what the top proprietary AI can deliver, and often better than previous generation tools.
A quick anecdote from the community: some users reported that DeepSeek Coder V2 is particularly good at mathematical programming problems, even better than GPT-4 in certain cases.
This might be due to the specialized training and perhaps incorporating DeepSeek Math capabilities. So if you’re dealing with code that involves complex math or algorithms, DeepSeek might have an edge in understanding and generating correct solutions.
Overall, the performance takeaway is that DeepSeek Coder has closed the gap with giants like OpenAI and Google on coding tasks.
It delivers high accuracy in code generation and can handle a wide array of challenges. This makes it not just an academic curiosity but a viable engine for real-world coding assistant applications.
DeepSeek Coder vs. GitHub Copilot vs. Amazon CodeWhisperer
How does DeepSeek Coder compare to the well-known coding assistants in the market? GitHub Copilot (powered by OpenAI models) and Amazon CodeWhisperer are two leading tools with somewhat different philosophies.
Let’s compare them across key dimensions to see the differences, benefits, and drawbacks of each:
| Model & Access | Open-source code LLM series (1.3B up to 33B; V2 up to 236B MoE). Available as downloadable models and via DeepSeek’s own platform. Users can run locally (with strong GPUs) or use an API. | Proprietary model (uses OpenAI Codex, now upgraded to GPT-4 for Copilot X). Access through a paid service integrated in GitHub/VS Code. Model itself is not accessible or tunable by users. | Proprietary service by AWS (underlying model details not public). Accessible via AWS Toolkit in IDEs or AWS Console. Closed model; improvements come from AWS updates. |
| License & Cost | Free & open-source – permissive license allows commercial use. No cost to use the model itself. (DeepSeek offers a free web app and may offer paid API for hosted use.) Hardware costs if self-hosting large models. | Subscription-based – Copilot is a paid service (about $10/month for individuals), though free for certain student or OSS developers. Closed license; output can have legal considerations (e.g. may suggest licensed code). | Free for individual use, as of 2023-2024. AWS offers CodeWhisperer free for personal use (just need an AWS account) and charges for professional use (part of AWS Professional tier, around $19/user/month for enterprise). The model is closed-source. |
| Integration | Flexible integration: No official IDE plugin, but can be used via API or command-line. DeepSeek provides a web-based chat for coding, and one can integrate the model in custom workflows. Some community integrations (e.g. via LangChain or editor plugins) may exist. Self-hosting gives full control (on-prem or private cloud). | Seamless IDE integration: Deeply integrated into Visual Studio Code, GitHub Codespaces, JetBrains IDEs, etc. It works as you type, no extra steps needed, and has a chat and CLI with Copilot X. Very polished UX since it’s productized by GitHub. Requires internet (connects to cloud API). | AWS ecosystem integration: Available in AWS Cloud9 IDE, VS Code (with AWS Toolkit extension), JetBrains via AWS extension. Works in real-time to suggest code. Also integrates with AWS services (can generate code snippets for AWS SDK calls, etc.). Requires internet/AWS connection. |
| Languages Supported | Extremely broad: 80+ languages in V1, expanded to ~338 languages in V2. Essentially covers most programming and scripting languages, including niche ones. Also bilingual in English and Chinese for prompts. | Major languages: Supports dozens of popular languages (the OpenAI model knows many languages, but Copilot’s strength is seen in Python, JavaScript, TypeScript, Go, Ruby, C#, C/C++, etc.). It may not do as well with very niche languages as those aren’t explicitly targeted. Primarily English prompts (though can likely handle other human languages to some degree). | Around 15 main languages: CodeWhisperer explicitly supports Java, Python, JavaScript, TypeScript, C#, Go, Ruby, PHP, C, C++, Kotlin, Rust, Scala, SQL, Shell, etc. Focus is on mainstream and cloud scripting languages. English is the primary interaction language. |
| Context Length | Long context: up to 16K tokens in V1, and up to 128K tokens in V2 Great for understanding large codebases or multiple files at once – fewer manual context switches. | Standard context (shorter): Copilot (with GPT-4) can handle around 8K token context in the editor, maybe up to 32K for Copilot Chat in limited beta. Generally, it looks at the current file and some surrounding files, but not an entire big project at once. | Moderate context: Not publicly stated, but CodeWhisperer focuses on the open file and perhaps some adjacent context. Likely a few thousand tokens at most. It may struggle with very large files or multi-file references beyond what’s open in the IDE. |
| Performance | State-of-the-art (open): Matches or exceeds top models on code benchmarks. Instruct 33B model beats GPT-3.5 on HumanEval, V2 model rivals GPT-4 on many tasks. Real-world, it can produce excellent solutions, but as an open model, actual performance will depend on your hardware and how you use it (prompts, etc.). | Excellent (closed): Copilot with GPT-4 is very powerful and tends to produce correct, context-aware suggestions most of the time. It benefits from OpenAI’s latest model improvements. In practice, Copilot has been trained on massive GitHub data (like Codex was on 50M repos), so it has a vast knowledge base. It may occasionally produce incorrect or insecure code, and performance can drop outside its training distribution, but overall regarded as the gold standard in coding assistants as of 2024. | Good for typical tasks: CodeWhisperer is competent in common scenarios – especially AWS-related code. It is reportedly slightly behind Copilot (GPT-4) in code quality for complex tasks, but not far off for routine suggestions. One unique strength is it checks code for security issues and will warn or fix vulnerabilities (e.g., it can detect credentials or common security pitfalls in the code it suggests). So performance includes not just accuracy but safer code. It might struggle with very intricate algorithms or less common libraries compared to Copilot/DeepSeek. |
| Unique Strengths | Control & Customization: You can fine-tune it on your own data, deploy on-premises, and ensure data privacy. Handles very large contexts (great for big projects). Open innovation – community can improve it. Also bilingual support (English/Chinese) could be a plus for multilingual dev teams. | User Experience & OpenAI tech: Extremely well-integrated into dev workflows – no friction to use. Benefits from OpenAI’s advanced research (especially GPT-4’s reasoning abilities). Copilot can also leverage ChatGPT plugins in Copilot Chat, etc. It’s constantly updated behind the scenes by OpenAI/GitHub with no effort from users. | AWS Integration & Security: Ties in nicely if you work with AWS – can autocomplete AWS API calls, infrastructure-as-code templates, etc. Has built-in security scanning – for certain languages, it can highlight potential vulnerabilities and even suggest fixes as you code. Also, it provides references for generated code if it’s similar to open-source code, which helps with license compliance (Copilot added a similar feature later as well). |
| Potential Drawbacks | Requires significant resources to run high-end models (the 33B or 236B models need a strong GPU server). The tooling and interfaces aren’t as polished out-of-the-box (it’s improving, but not as plug-and-play as Copilot). Being open-source, you manage updates and hosting. Support/community is growing but smaller than a big product’s user base. | Closed source means you rely on GitHub/Microsoft for improvements and can’t self-host. Data privacy could be a concern (your code is sent to the cloud). There have been concerns about it suggesting copyrighted code verbatim (rare, and GitHub implemented a filter, but still a legal grey area). Also, it’s a paid service for continued use. | Tied to AWS – if you’re not using AWS tools, it’s less convenient. Fewer supported languages than others. It may not be as cutting-edge on very complex code generation. And as a cloud service, using it means your code flows through AWS servers (which some companies might restrict). |
In summary, DeepSeek Coder stands out if you value openness, customization, and cutting-edge performance without vendor lock-in.
It’s ideal for organizations that need a private coding assistant (for proprietary code) or anyone who wants to experiment with the model itself.
It also handles certain scenarios (very large contexts, many languages) better than the others thanks to its design.
However, it might require more effort to integrate into your workflow and sufficient compute resources to run smoothly.
GitHub Copilot, on the other hand, is all about convenience and integration – it’s currently the most widely used because it “just works” in your editor with minimal setup and leverages extremely powerful OpenAI models.
For individual developers who can afford $10/month and are fine with a cloud service, Copilot offers a polished experience and top-tier suggestions.
Microsoft and OpenAI’s ecosystem also means continuous improvements (e.g., Copilot X bringing chat, voice, etc., using GPT-4).
The downside is you’re relying on a closed model and sending code to the cloud, which not every company permits.
Amazon CodeWhisperer is a strong free alternative, especially if you’re already in AWS’s orbit. It being free for personal use lowers the barrier to try.
It performs well for general tasks and is particularly helpful with AWS-centric development (like writing AWS Lambda functions, or step functions code, etc., where it might have been optimized).
Its security features are a differentiator – it will underline potential security issues in its suggestions, and it won’t suggest copyrighted code without attribution (it can point you to the source if a snippet it’s giving is closely derived from known open-source code).
These are thoughtful features for professional developers. CodeWhisperer is slightly less ambitious in scope than DeepSeek or Copilot – it’s more targeted at making AWS developers more efficient.
Ultimately, the “best” coding assistant depends on your needs:
- If you need full control and privacy, DeepSeek Coder is unmatched.
- If you want the most powerful completions with zero setup, Copilot is a strong choice.
- If you prefer a free solution and work a lot with AWS or worry about security scanning, CodeWhisperer is worth a look.
Some developers even use multiple: e.g., Copilot for everyday coding, but a local DeepSeek instance for specific large-context tasks or when working offline.
The good news is these tools are not mutually exclusive – you can pick the right tool for the job.
Getting Started with DeepSeek Coder
If you’re intrigued by DeepSeek Coder and want to try it out, here are a few ways to get started:
- DeepSeek Coder Web Chat: The easiest way to experiment is via DeepSeek AI’s official website. They offer a web interface where you can chat with DeepSeek Coder – similar to a ChatGPT style playground, but tailored for coding. You can enter prompts or coding questions and get answers/completions in your browser, without installing anything. This is great for a quick test or occasional use. (Note: you may need to sign up for an account on their site, and there might be usage limits since it’s a free service.)
- Hugging Face Models: DeepSeek Coder models are available on HuggingFace Hub, which means you can download the model weights and run them locally or in the cloud. For example, the DeepSeek-Coder-6.7B or 33B models can be loaded with the Hugging Face Transformers library. Keep in mind the hardware requirements: the 6.7B model might run on a single high-end GPU (with ~16GB VRAM) with some optimization, but the 33B likely needs 2+ GPUs or 30GB+ VRAM (perhaps using 8-bit quantization or model parallelism). Hugging Face’s model cards and the DeepSeek GitHub provide instructions on how to load the model in Python. For instance, after installing
transformers, This would load the 6.7B base model and generate a completion. Adjust model name to the instruct variant for better prompt following. The DeepSeek-Coder-V2 models (especially the 236B one) have even steeper requirements – the full model is truly massive (21B active params but 236B total weights, which might exceed 200GB of memory). For those, you’d likely use an 8-GPU server or a specialized inference service. The good thing is the team also provides a 16B “Lite” V2 model which has much fewer active parameters (2.4B active) – this one is more feasible to run and still yields great performance - Docker or API Deployments: Check DeepSeek’s GitHub repositories for any docker images or scripts to serve the model. Often, projects like this provide a way to run a local API server. This would allow you to integrate DeepSeek Coder into an IDE by pointing your editor to the local API (some extensions let you specify a local endpoint for completions). At the very least, you can run the model and send HTTP requests to it. Community projects might also exist that wrap DeepSeek Coder into an easy-to-use local app.
- DeepSeek Platform and Apps: DeepSeek AI appears to have an ecosystem (their site mentions a DeepSeek App and an API platform). It’s likely they offer an API key for their hosted model, so you don’t need to run it yourself. This would be similar to using OpenAI’s API – you make calls to their endpoint with your prompt and get a completion. Pricing for this isn’t clear (it might still be in beta or free). For companies, using their managed API could be a way to pilot DeepSeek Coder without heavy infrastructure. Always ensure to review their privacy and data policies if using a hosted service.
- Integration in Workflow: If you want to integrate DeepSeek Coder into your coding workflow, one straightforward method is via editor extensions that support custom LLMs. For example, there are VS Code extensions that allow using local GPT-like models for autocompletion. By configuring those to use DeepSeek (via a command-line or API call), you can emulate a Copilot-like experience. Another route is using ChatGPT-style UIs like ChatUI or LangChain to interface with the model – those can provide a nice chat where you load your code and ask questions. This requires some technical setup, but many AI enthusiasts have done similar integrations for other open models like Code Llama or StarCoder, and the process for DeepSeek would be analogous.
- Fine-Tuning or Customizing: If you have specific needs, you can fine-tune DeepSeek Coder on your data. The GitHub repo provides a script for fine-tuning (
finetune_deepseekcoder.py). Suppose you want the model to be particularly good at your company’s internal frameworks or to follow your coding style – you can feed it Q&A or code completion examples from your own codebase and continue training it (with a smaller learning rate). This does require machine learning expertise and resources, but it’s a powerful option. Even a few hundred fine-tuning examples can steer the model to be more useful in a niche domain.
Before diving in, make sure to read the official Technical Report (on arXiv) and the GitHub README for DeepSeek Coder.
They contain lots of details on usage and limitations. Also join the DeepSeek Discord community if you have questions; open-source projects often have active user groups.
Lastly, keep an eye on updates: AI models evolve quickly. DeepSeek AI has hinted at continuing improvements (their site references versions V3, R1 models, etc.).
It’s possible that later versions or new models will come, further boosting capabilities. By getting started with V1 or V2 now, you’ll be well-positioned to leverage those future upgrades.
Conclusion
DeepSeek Coder represents a significant leap in the world of AI coding assistants – bringing top-tier code generation and understanding capabilities into the open-source domain.
For years, the most advanced coding AIs were proprietary, hidden behind APIs and paywalls.
DeepSeek Coder turns that notion on its head by providing a freely available model that any developer or organization can use.
Its strong performance on benchmarks (even outperforming GPT-3.5 and reaching toward GPT-4 in coding tasks) demonstrates that open models can compete with the industry’s best.
More importantly, it empowers users with choice: choice to run the model locally, choice to fine-tune it, and choice to integrate it in creative ways beyond what closed platforms offer.
For developers and tech companies, DeepSeek Coder opens up new possibilities.
Startups could build their own AI pair programmer into their IDE or devops pipeline without relying on a third-party. Educators could deploy an offline coding mentor for students.
Researchers can study and improve the model, pushing the field of code intelligence forward.
All of this contributes to an ecosystem where AI is not just a service you consume, but a tool you can own and shape.
That said, DeepSeek Coder is not a silver bullet. Like all AI models, it can produce incorrect or insecure code if prompted ambiguously.
It may sometimes overly confident output that needs debugging. Users should treat its suggestions as helpful starting points, to be reviewed and tested just as they would review a junior developer’s code.
Responsible usage – including testing generated code and being mindful of licensing (if it produces code very similar to known examples) – remains important.
The advantage with DeepSeek is you can actually inspect what it was trained on and adjust it, which increases trust in the long run.
In comparing with tools like Copilot and CodeWhisperer, we saw that each has its niche. It’s not so much about one being universally better, but about aligning the tool with your needs.
The fact that an open model can now stand shoulder to shoulder with commercial giants is a win for the developer community at large.
It means more innovation, faster adoption of AI in coding, and potentially lower costs and barriers to access these powerful assistants.
Moving forward, we can expect coding models to get even better – perhaps reaching a point where they reliably handle most mundane coding tasks and even complex ones with minimal guidance.
DeepSeek Coder is part of that journey, and by using it, developers also contribute feedback and improvements to the model (especially if you fine-tune or report issues on GitHub). It’s a collaborative progress.
To wrap up, DeepSeek Coder is an exciting development for anyone in software development or AI:
- If you’re a developer, it’s worth trying out to see how it can boost your productivity or help you learn.
- If you’re a team lead or CTO, consider how an open-source AI like this might fit into your toolchain, offering flexibility that a SaaS solution might not.
- If you’re a student or hobbyist, this is a chance to play with a cutting-edge model for free and perhaps even contribute to its evolution.
The age of “AI pair programmers” is truly here. With tools like DeepSeek Coder in your toolkit, you can let the code (mostly) write itself, while you focus on the creative and critical thinking aspects of development. Happy coding!