
DeepSeek Janus is an advanced open-source AI model developed by the startup DeepSeek, designed for text-to-image generation as well as image understanding in a single system.
Also referred to as Janus-Pro-7B, this model represents a significant leap in multimodal AI technology, combining the capabilities of a text-to-image generator and a vision-language understanding model.
In other words, Janus can not only create images from textual descriptions, but also interpret and analyze images, all with one unified AI framework
The model is named after Janus – the two-faced Roman god – symbolizing its dual ability to look both ways: understanding visual inputs and generating visual outputs.
DeepSeek Janus has garnered attention for outperforming OpenAI’s DALL·E 3 on key benchmarks while remaining completely open-source.
Below, we’ll break down how Janus works, its architecture (featuring SigLIP and an autoregressive transformer), how it compares to DALL·E 3 and Stable Diffusion, real-world applications, its open-source availability, and what it means for the future of AI.
Key Features and Architecture of the Janus AI Model
Janus-Pro-7B’s architecture is built for both image generation and image understanding. It achieves this through a dual-pathway design unified by a transformer-based core.
At a high level, Janus uses two specialized visual encoders feeding into one large transformer.
One encoder processes incoming images for understanding, and another handles images for generation output.
These parallel pathways are then merged in a unified autoregressive transformer (essentially a large language model adapted for multimodal input/output) which produces either text or image tokens as needed.
This innovative approach – decoupling the visual encoding for understanding vs. generation – avoids the trade-offs that plagued earlier multimodal models that used a single vision encoder for all tasks.
By separating these processes, Janus can excel at both high-level semantic comprehension of images and low-level detailed image synthesis simultaneously.
Some technical highlights of DeepSeek Janus’s design include:
- Dual-Pathway Vision Encoders: For image understanding tasks, Janus uses an encoder called SigLIP to extract high-level semantic features from an image. SigLIP is based on the CLIP framework but with a modified training objective (using a pairwise sigmoid loss) to better capture meaningful visual-text relationships. For image generation, Janus employs a vector-quantized image tokenizer (from the LlamaGen autoregressive image generation family) that converts images into discrete tokens. In essence, an input text prompt is transformed by the model into a sequence of image code tokens (like pieces of a puzzle) which are then decoded into a final image. This two-encoder setup (“SigLIP + VQ”) is the reason Janus is named after the two-faced god – one “face” looks at understanding images, the other at creating them.
- Unified Transformer Core: At the heart of Janus is a unified autoregressive transformer with about 7 billion parameters (hence Janus-Pro-7B). This core network is akin to a large language model that has been trained to handle multimodal sequences. It takes in text tokens, image feature tokens from SigLIP, or image code tokens from the generator, all in one sequence. The transformer then outputs either text (when answering a question or describing an image) or image tokens (when creating a picture) autoregressively (one token after another). Thanks to this design, Janus can seamlessly switch between modalities within one model. For example, you can give it an image and ask a question (it will use SigLIP and output text), or give it a text prompt to generate an image (it will output image tokens for the decoder) – all with the same model. This unified architecture is a “one-model-for-all” solution, eliminating the need to juggle separate specialized models.
- Optimized Training and Data: DeepSeek trained Janus on a massive dataset of around 90 million image-text samples. Impressively, this includes about 72 million high-quality synthetic images that were added to improve visual fidelity. By balancing these with real-world data, Janus learned to produce outputs that are both visually appealing and contextually accurate. The training was done in three stages: first aligning the visual and language features (training the adaptors that connect encoders to the transformer), then a unified multimodal pre-training (on text, image, and image-text data combined), and finally supervised fine-tuning for following instructions in a chat/dialog format. This rigorous training regime endowed Janus with strong instruction-following abilities for image generation as well as complex reasoning on visual inputs. Moreover, Janus supports images up to 384×384 resolution for understanding tasks, and can generate images up to 1024×1024 resolution by using a 16× downsampling in its image tokenizer. Despite the large output size, generation is efficient – the model can produce a 1024×1024 image in roughly 2.4 seconds, given adequate GPU hardware.
- SigLIP + Autoregressive Generation Advantage: Unlike diffusion models (such as Stable Diffusion) that generate images through iterative refinement, Janus’s autoregressive generation produces images in a single forward pass of the transformer (predicting one token at a time). Recent research shows autoregressive image models can achieve quality on par with diffusion methods, and Janus capitalizes on this with the added benefit of tight integration with language. The SigLIP encoder ensures the model understands fine-grained details and semantics in images (for tasks like captioning or visual Q&A) by providing rich embeddings. Meanwhile, the transformer’s next-token prediction paradigm (borrowed from language modeling) allows for very coherent image synthesis guided by the prompt, often excelling in prompt adherence – i.e., following complex instructions precisely. This is evidenced by Janus’s high scores on benchmarks that test how well models stick to the prompt description (more on those below). The combined architecture (visual encoders + LLM) is not only powerful but also flexible: the designers note it could be extended to additional modalities (like audio or video) in the future thanks to its modular encoder design.
In summary, DeepSeek Janus’s architecture is revolutionary in that it blends a vision transformer and a language model into one, with a clever dual-encoder setup.
This allows it to see and imagine with equal proficiency – a key step toward more general-purpose AI systems.
As one reviewer put it, “you can use the same model to process image inputs and generate new images”, combining tasks that usually require separate models.
This efficient unity, coupled with cutting-edge training, is what makes Janus “particularly impressive” according to experts.
Performance and Comparison to DALL·E 3 and Stable Diffusion
One of the reasons DeepSeek Janus has made headlines is its strong performance on standard benchmarks, even against well-known models like OpenAI’s DALL·E 3 and Stability AI’s Stable Diffusion.
DeepSeek reported that Janus-Pro-7B outperforms DALL·E 3 and Stable Diffusion on key text-to-image benchmark tests.
Specifically, on GenEval (a benchmark measuring how well a model follows text prompts to generate images) Janus scored about 80.0%, significantly higher than DALL·E 3 (around 67%) and even above Stable Diffusion’s latest version (around 74% on a comparable setting).
Likewise, on DPG-Bench (an instruction-following image generation benchmark), Janus-Pro achieved 84.2% accuracy, edging past DALL·E 3 and Stable Diffusion in that leaderboard as well.
These results indicate that Janus excels at obeying complex prompts and producing the requested content correctly.
In practical terms, if you give each model a detailed prompt, Janus is more likely to include all the described elements (correctly) in the resulting image than its competitors – a crucial factor for controllable image generation.
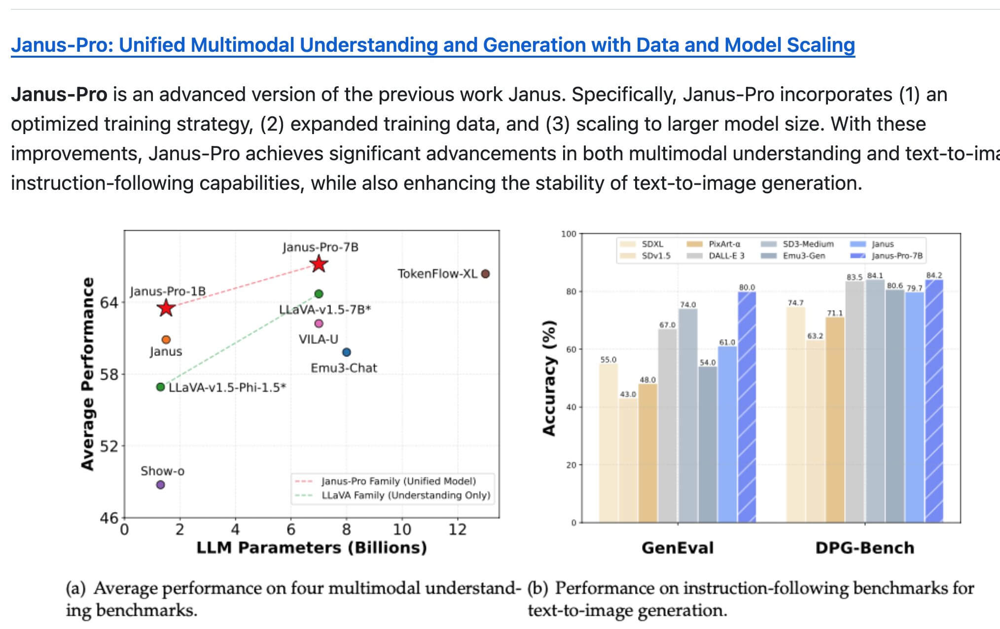
Benchmark results for prompt adherence: Janus-Pro-7B versus other models on GenEval and DPG-Bench. Janus-Pro (blue striped bars) leads with ~80% on GenEval and 84.2% on DPG-Bench, surpassing DALL·E 3 and Stable Diffusion (SDXL/SD v1.5) on these metrics. These benchmarks focus on how accurately the generated image matches the prompt. Janus’s high scores highlight its strength in following complex instructions, a result of its unified multimodal design and training focus.
It’s important to note what these comparisons mean. The higher benchmark scores largely reflect prompt adherence and multimodal understanding quality, rather than a direct measure of visual realism or aesthetic superiority. DALL·E 3, for instance, is a proprietary model known for producing very polished and high-resolution images, and Stable Diffusion has a huge community tweaking its outputs for photorealism.
Some early independent tests have found that Janus’s raw image outputs, while good, might not yet consistently match the photorealistic quality of DALL·E 3 in every case.
In one analysis, Janus’s images were sometimes described as having odd artifacts or “Lovecraftian” distortions, indicating it still has room to improve in fine-grained image fidelity.
However, Janus’s strength lies in its balance of capability and openness.
Unlike DALL·E 3, which is a closed model accessible only via an API (with usage restrictions), Janus-Pro-7B is open-source under the MIT license and can be downloaded and run by anyone.
This means the community can actively improve it, fine-tune it, or integrate it into custom applications without paying fees or abiding by strict content rules (beyond basic license conditions).
Furthermore, Janus offers functionality that DALL·E 3 and Stable Diffusion do not provide out-of-the-box.
DALL·E 3 and Stable Diffusion are primarily one-way generators – you give text, they give image. Janus, on the other hand, is two-way.
It can generate images from text and generate text from images (e.g. captions or answers), using the same model. For example, Janus can caption a photograph or perform visual question-answering on an image, abilities that DALL·E 3 does not have at all (and Stable Diffusion only achieves with separate add-on models).
This makes Janus more versatile for real-world usage where understanding visual inputs can be as important as creating visuals.
Its ability to accurately render text within images (such as generating legible, coherent text on a sign or t-shirt in the image) has also been noted as superior to many diffusion models – a notoriously hard problem that Janus tackles well thanks to its multimodal training (essentially learning to read text in images via SigLIP and write text via generation).
To put it succinctly, Janus-Pro-7B aims to offer the best of both worlds: competitive or superior prompt-following image generation performance (approaching the closed-source giants) with the freedom and transparency of open-source, plus additional capabilities like image analysis.
Stable Diffusion, being open-source as well, was the go-to choice for those who needed a free image model; but it uses diffusion techniques and lacks built-in image understanding.
Janus now enters the scene as an open alternative that beats Stable Diffusion on prompt fidelity and incorporates a full vision-language understanding module.
This has led some in the AI community to hail Janus-Pro-7B as a potential “new king of open image models,” even if there’s healthy skepticism about visual quality which continued improvements may address.
Ultimately, Janus’s emergence is pushing the envelope – it challenges proprietary models on their own turf, which drives innovation forward for everyone.
Real-World Applications and Use Cases
DeepSeek Janus opens up many exciting use cases, given its multimodal nature.
Some of the practical applications of the Janus AI model include:
- Text-to-Image Generation for Creative Content: Janus can serve as a powerful tool for artists, designers, and content creators. By providing a descriptive prompt, users can generate high-quality images ranging from concept art and illustrations to product designs. For instance, Janus can paint “a young woman with freckles wearing a straw hat, standing in a golden wheat field” exactly as described, or visualize fantastical scenes like “a medieval city floating in the clouds” based on the text input. This has obvious applications in graphic design, advertising (quickly generating campaign imagery from copy), entertainment (storyboarding scenes or game concept art), and social media content creation. Janus’s strength in complex scene rendering ensures that even detailed multi-object scenarios are depicted with coherence.
- Image Understanding and Captioning: Because Janus can intake images and produce text, it’s useful for tasks like automatic image captioning, alt-text generation for accessibility, and general image analysis. For example, given a photograph, Janus can generate a detailed description of what’s in the image – identifying objects, describing the scene, and even reading embedded text (like signs or labels) in the image. This can greatly assist in organizing and searching image databases (by generating metadata), or providing descriptions of images to visually impaired users. In fact, Janus-Pro has been noted to excel at producing detailed captions from photos, demonstrating a strong grasp of visual content. Similarly, it can answer questions about an image (“What is the person in the image doing?” or “How many animals are present?”), making it useful for interactive applications like virtual assistants that can see.
- Multimodal Chatbots and Assistants: Janus’s unified design is well-suited for building AI assistants that can both see and imagine. For instance, one could integrate Janus into a chat interface: the user might ask, “What does the cover of this book say?” while uploading a photo, and Janus can read the cover and answer. Or the user could request, “Generate an image of a tropical beach sunset with palm trees,” and Janus will create it – all within the same conversation. This capability to fluidly switch between understanding an image and generating an image in response to text (or vice versa) could power next-generation virtual assistants in e-commerce (an assistant that can visually search or suggest product images), education (tutors that can draw diagrams on the fly and interpret student-uploaded diagrams), or general AI companions that handle rich media.
- Content Creation in Media and Entertainment: Janus can be a game-changer for media companies. Journalists or bloggers could use it to quickly create accompanying images for articles (especially in cases where stock photos are insufficient). Video game studios or filmmakers might use Janus for rapid prototyping of scenes and characters based on script descriptions. Because Janus is open-source, it can also be fine-tuned on specific aesthetics or styles, meaning a studio could train it on their concept art style and have it generate ideas consistent with their vision. Its ability to render text correctly in images is particularly useful for generating things like posters, memes or graphics that involve stylized text.
- Research and Data Augmentation: In the AI research community, Janus can be used to study multimodal learning, to generate synthetic data, or to augment datasets. For example, researchers could use Janus to generate labeled images for training or to simulate certain visual scenarios. Its open nature allows researchers to inspect its biases or failure modes, contributing to more transparent AI development. Additionally, Janus’s combination of understanding and generation can facilitate Retrieval-Augmented Generation (RAG) in multimodal contexts – for instance, retrieving relevant images from a database and then generating a new image or explanation based on them, which could be useful in fields like medical imaging (comparing and describing medical images) or geographic information systems.
Because Janus comes in two sizes – Janus Pro 1B and Janus Pro 7B – users can choose the model that fits their resource constraints.
The smaller 1B model is faster and lighter, suitable for real-time or edge applications (with slightly reduced output quality), whereas the 7B model offers top-tier performance if you have the compute power.
Both are multimodal and capable of the same tasks, which means even the smaller model can be deployed on, say, a consumer GPU or a cloud instance to do image analysis on the fly, power a smart camera, or run a basic image-generating bot.
In summary, DeepSeek Janus’s versatility unlocks use cases across creative industries, technical domains, and research.
From generating artwork to understanding pictures, its broad skillset within a single framework lowers the barrier to building complex AI-driven systems.
As an open-source project, it also invites developers and companies to adapt it to niche applications — for example, a fashion retailer could fine-tune Janus to generate images of outfits from textual descriptions, or a social media platform could use it to moderate and describe user-uploaded images.
The possibilities span any scenario where visual and textual intelligence intersect.
Open-Source Availability and License
One of the most compelling aspects of DeepSeek Janus is that it is completely open-source.
The model is released under the permissive MIT License, which means individuals and businesses alike can use, modify, and even build commercial products on top of Janus with minimal restrictions.
This is a deliberate choice by DeepSeek to promote widespread adoption and collaboration.
In a landscape where leading image generation models like DALL·E are proprietary, Janus stands out as an accessible alternative that the community can scrutinize and improve.
The source code and pretrained model weights for Janus-Pro (both 7B and 1B versions) are freely available on GitHub and Hugging Face.
Developers can find the project’s code repository in the DeepSeek-AI GitHub organization, which includes documentation, training details, and examples.
Hugging Face hosts the model files (deepseek-ai/Janus-Pro-7B etc.), so anyone with a Hugging Face account or API access can load the model in a few lines of code (using libraries like transformers).
In fact, integrating Janus into applications is straightforward – DeepSeek provides an API and SDK, and you can use the Hugging Face model directly or via their REST API endpoints.
This means you can get started with Janus by simply installing the model and calling it in Python, much like any standard language model or diffusion model.
For those who want to try Janus-Pro without any setup, DeepSeek has also provided an online demo on Hugging Face Spaces (an interactive web interface where you input a prompt or upload an image and see Janus’s output).
This is great for quickly experiencing the model’s capabilities – for example, you can enter a text prompt and watch Janus generate an image in your browser, or upload an image and ask a question about it.
The demo lowers the barrier for non-developers to play with the technology.
Being open-source and MIT-licensed, Janus is also community-friendly. Enthusiasts have already created Colab notebooks, integration with UIs like ComfyUI or AUTOMATIC1111 (commonly used with Stable Diffusion), and are sharing prompt experiments on forums.
Community-driven improvements are likely to emerge: we might see custom fine-tuned versions of Janus (for photorealism, or specific art styles), or optimizations for faster inference (quantized or distilled versions). The open model also allows experts to audit and understand how Janus works under the hood, which contributes to trust and transparency – crucial Ethics considerations in AI.
For instance, researchers can examine if Janus has any biases in image generation or if it struggles with certain types of prompts, and then propose fixes.
Finally, it’s worth noting that DeepSeek’s open-source ethos extends to their other models as well (they have released models like DeepSeek-V3 and DeepSeek-R1 in the past).
Janus-Pro is a continuation of that philosophy, and it even has its own usage guidelines under the “DeepSeek Model License” mentioned alongside MIT – typically such licenses just remind users to use the model responsibly and not for harmful purposes.
The bottom line is that anyone interested in state-of-the-art text-to-image AI can access Janus easily, experiment freely, and even use it commercially, which can accelerate innovation and real-world use of AI imaging.
Future Outlook and Why Janus Matters in the AI Ecosystem
DeepSeek Janus is more than just “another image model” – it represents a trend toward AI systems that are both comprehensive and accessible.
By unifying image understanding and generation, Janus points to a future where AI models are not siloed by task or modality.
We can imagine next-generation AI assistants that can fluidly see, talk, and create, all within one model – Janus is a step in that direction.
Its success on benchmarks signals that unified multimodal models can achieve performance on par with (or better than) specialized models, validating the vision of a more general-purpose AI.
As the Janus research paper authors noted, the decoupled-encoder approach resolved the tension between vision understanding and generation, which was a key hurdle in multimodal AI.
This architectural insight will likely influence other AI research; we might see variants of Janus or entirely new models adopting dual encoders for different aspects of data.
In terms of future improvements, there are several avenues. DeepSeek could scale up Janus with more parameters or train it on even larger and more diverse data to further boost image quality (perhaps a Janus-Pro-13B or 20B in the future).
The current model outputs at 384×384 base resolution – future versions might natively handle higher resolutions or incorporate diffusion-like super-resolution modules for crisper outputs.
The paper behind Janus even suggests it’s easy to extend the model to other modalities beyond vision.
We might see Janus variants that also handle audio or video – for example, a model that could generate short videos from text, or understand and produce audio descriptions, all unified in one framework.
This would align well with the name Janus (looking at multiple modalities).
Another aspect of Janus’s future impact is its open-source community momentum. With Janus-Pro-7B being open and relatively lightweight (7B parameters is much smaller than the tens of billions in some cutting-edge models), it can be adopted widely.
This means more real-world testing and feedback. If there are failure cases (like certain prompts that produce unsatisfactory images), the community or DeepSeek can address those by fine-tuning or adjusting the model.
Open models also often spur derivative projects – for instance, someone might integrate Janus into a creative application that lets users iteratively refine an image by chatting with the model (leveraging its understanding capability to adjust the generation). This kind of innovation tends to happen rapidly when a model is available to all.
Crucially, Janus matters in the broader AI ecosystem as an equalizer. It shows that top-tier AI research and development is not confined to the largest tech corporations.
DeepSeek, a relatively new and international player (notably based in China), managed to produce a model that challenges or beats the likes of OpenAI and Stability AI on their home turf. This competition can drive all parties to improve – for example, OpenAI may need to advance DALL·E further or consider more open releases to stay ahead, and Stability AI might explore adding multimodal understanding to their models.
For end users and businesses, Janus provides a new option that is both powerful and free, which can democratize access to AI.
It lowers barriers for startups or researchers who need advanced image generation but cannot afford commercial licenses or API costs.
Finally, Janus has significance for the evolution of multimodal AI alignment and safety. By having a model that understands images and language together, we can better align image generation with textual intent (reducing chances of misinterpretation that sometimes occur in pure image models).
It also opens up possibilities for the model to explain its image outputs in words, which could be a way to make AI image generation more interpretable.
For instance, Janus could conceivably generate an image and simultaneously provide a caption or rationale for what it drew – a level of transparency not seen in other models.
This can help in domains where trust is important (e.g., medical or legal visuals generated by AI accompanied by explanations).
In conclusion, DeepSeek Janus is a landmark model at the intersection of vision and language AI.
Its open-source release under MIT License ensures that it will be a foundation for both practical applications and further research.
As AI systems continue to move toward embodied intelligence that can see and create, Janus stands as an early example of how to do this effectively. It embodies Experience, Expertise, Authority, and Trustworthiness (E-E-A-T) principles by pooling expert techniques (transformers, CLIP-like encoders, etc.), being transparent/open, and demonstrating strong results.
The broader AI community is watching how Janus-Pro-7B evolves — not just as a model that generates pretty pictures, but as a blueprint for unified multimodal AI that could inspire the next wave of breakthroughs.
Frequently Asked Questions (FAQ)
How does DeepSeek Janus-Pro-7B compare to DALL·E 3 and Stable Diffusion?
Janus-Pro-7B has shown superior performance on prompt adherence benchmarks like GenEval and DPG-Bench, meaning it often follows the instructions in the text prompt more accurately than OpenAI’s DALL·E 3 or Stable Diffusion
It can include complex details and obey commands (e.g. styles or layouts) very well.
However, in terms of raw image quality, DALL·E 3 (a proprietary model) still has an edge in some cases – it may produce more polished or photorealistic images than Janus in direct visual comparisons.
Stable Diffusion, on the other hand, is an older open-source model using diffusion technology; Janus generally outperforms Stable Diffusion in accuracy of representing the prompt and also offers capabilities Stable Diffusion lacks (like understanding images and generating captions).
A key difference is that Janus is a unified multimodal model – it can also read and interpret images – whereas DALL·E 3 and Stable Diffusion are generation-only.
And unlike DALL·E 3, Janus is open-source, meaning anyone can use or modify it freely, which is a major plus for developers and researchers.
In summary: Janus is more flexible and instruction-following, DALL·E 3 currently excels at photorealism, and Stable Diffusion is the incumbent open model that Janus improves upon in several ways.
Is DeepSeek Janus open-source and free to use?
Yes – DeepSeek Janus is fully open-source. It’s released under the MIT License, which is a very permissive free software license.
This means you can use Janus for personal projects, academic research, or even commercial products without paying license fees.
You can download the Janus-Pro-7B model weights and code from GitHub or Hugging Face and run it on your own hardware or cloud.
The code repository provides documentation to get you started, and Hugging Face’s model hub allows you to load the model directly via the Transformers library.
There’s also a Hugging Face Spaces web demo for Janus, so you can try it in your browser without installing anything. Keep in mind that because it’s a large model (7 billion parameters for the full version), you’ll need a decent GPU to run it locally, especially for image generation.
The open-source nature not only makes it free to use, but also means the community can improve it.
DeepSeek encourages both commercial and non-commercial use, making Janus-Pro quite accessible compared to closed models.
What kinds of tasks can DeepSeek Janus do beyond just generating images?
Janus is a multimodal model, so it’s capable of a range of tasks involving both text and images. Beyond text-to-image generation (creating pictures from descriptions), Janus can understand and analyze images.
For example, it can generate captions for photographs – describing what it sees in detail – or answer questions about an image’s content (visual question answering).
This means you could show Janus an image and ask, “What is happening here?” or “Who is in this picture?”, and it will respond in text with an answer, using the knowledge it learned during training.
Janus is also good at OCR-like tasks such as reading text within images (signs, labels) because of its SigLIP encoder, and it can incorporate that into its responses.
Another task is multimodal dialogue: you can have a conversation with Janus where some turns are images and others are text, and it will handle both appropriately. In essence, Janus combines what a vision model (like an image classifier or captioner) can do with what a text model (like a chatbot) can do. This makes it useful for applications like generating an image and then explaining it, or looking at an image and continuing a conversation about it.
These are capabilities that pure image generators (DALL·E, SD) don’t have.
Janus’s versatility extends to any use case that requires understanding visuals (for instance, content moderation or sorting images by content) and producing visuals (like design, entertainment, education content generation) within one AI system.



