Deep-seek.chat is an independent website and is not affiliated with, sponsored by, or endorsed by Hangzhou DeepSeek Artificial Intelligence Co., Ltd.

What Is DeepSeek? A Complete Guide to the Next-Generation Open AI Model
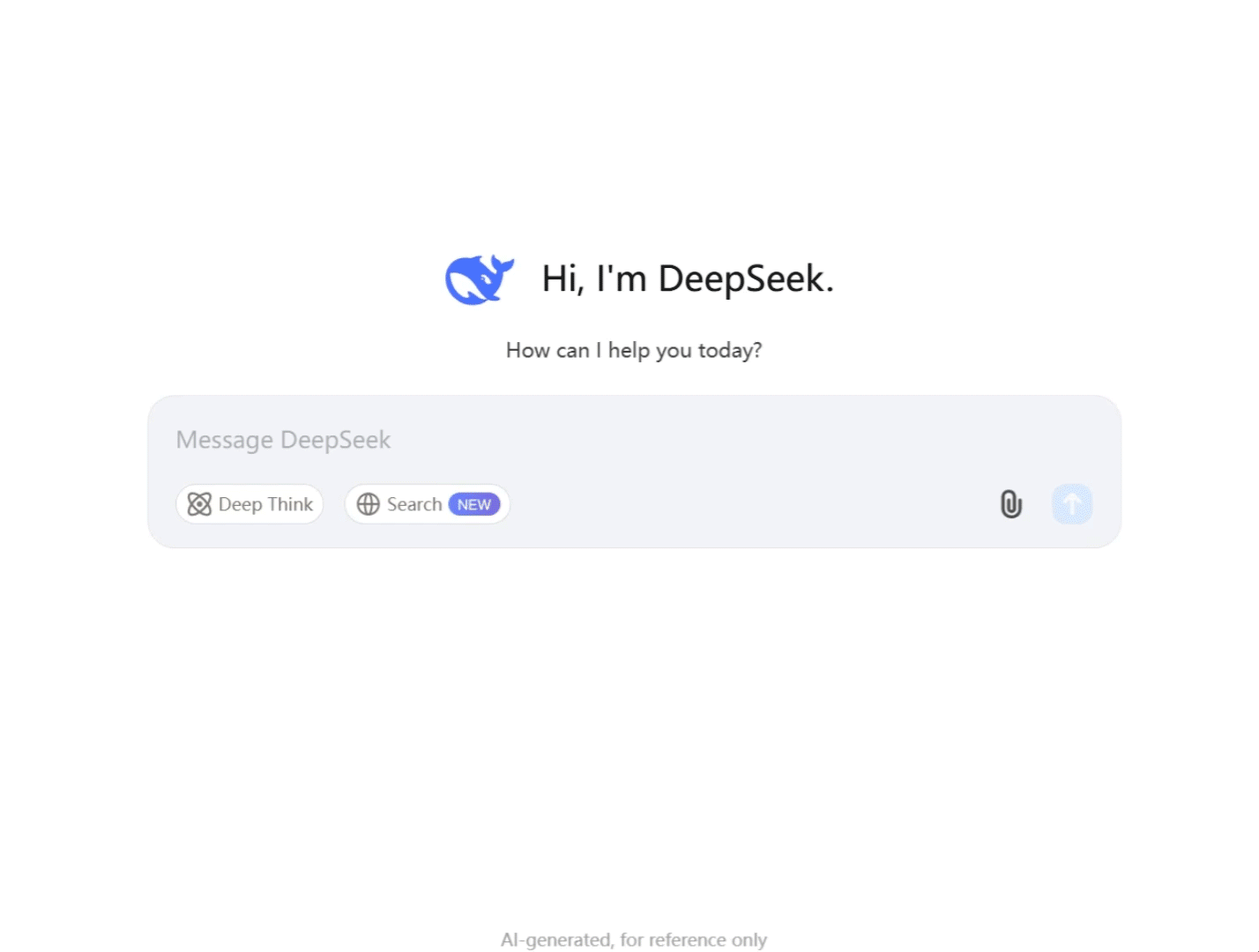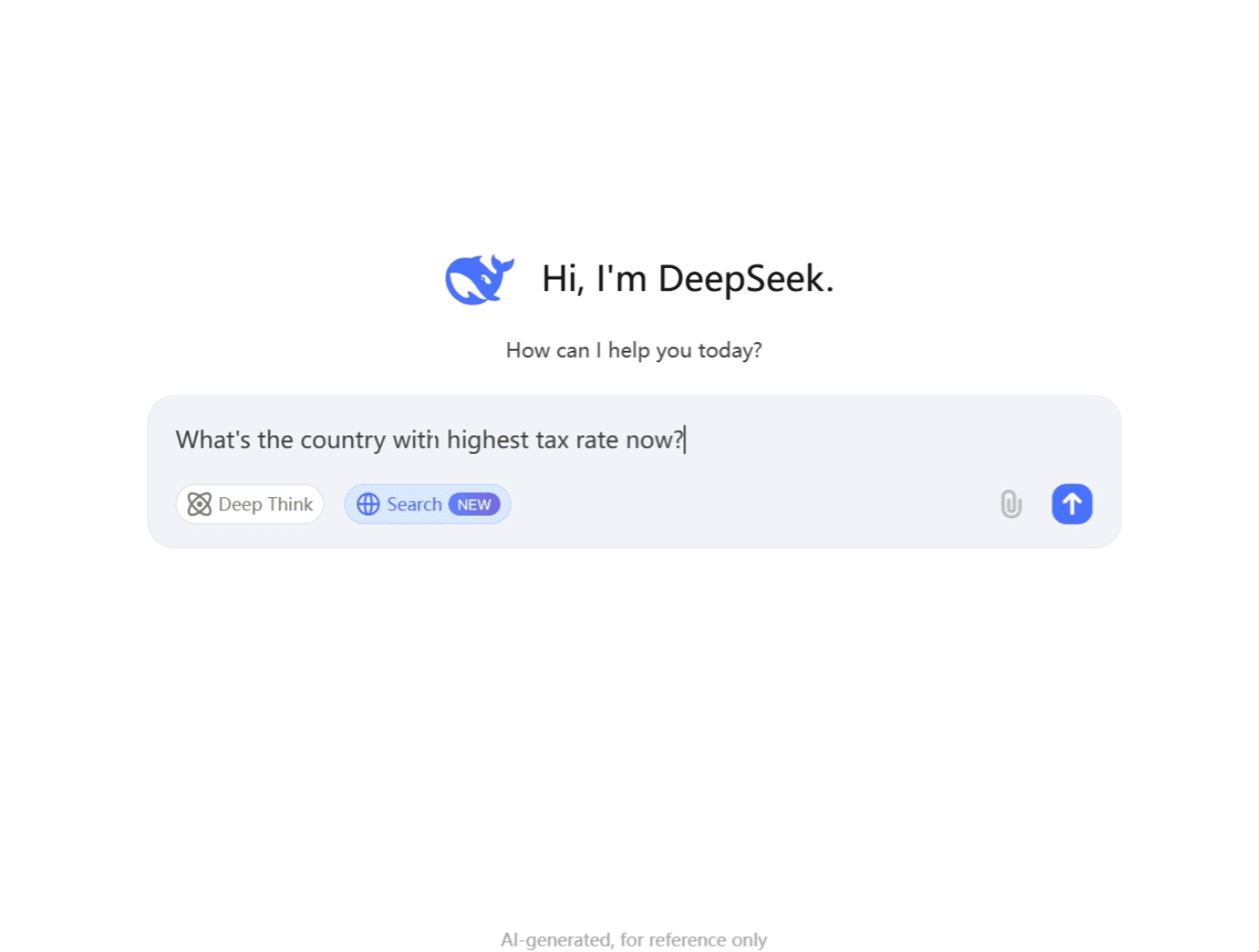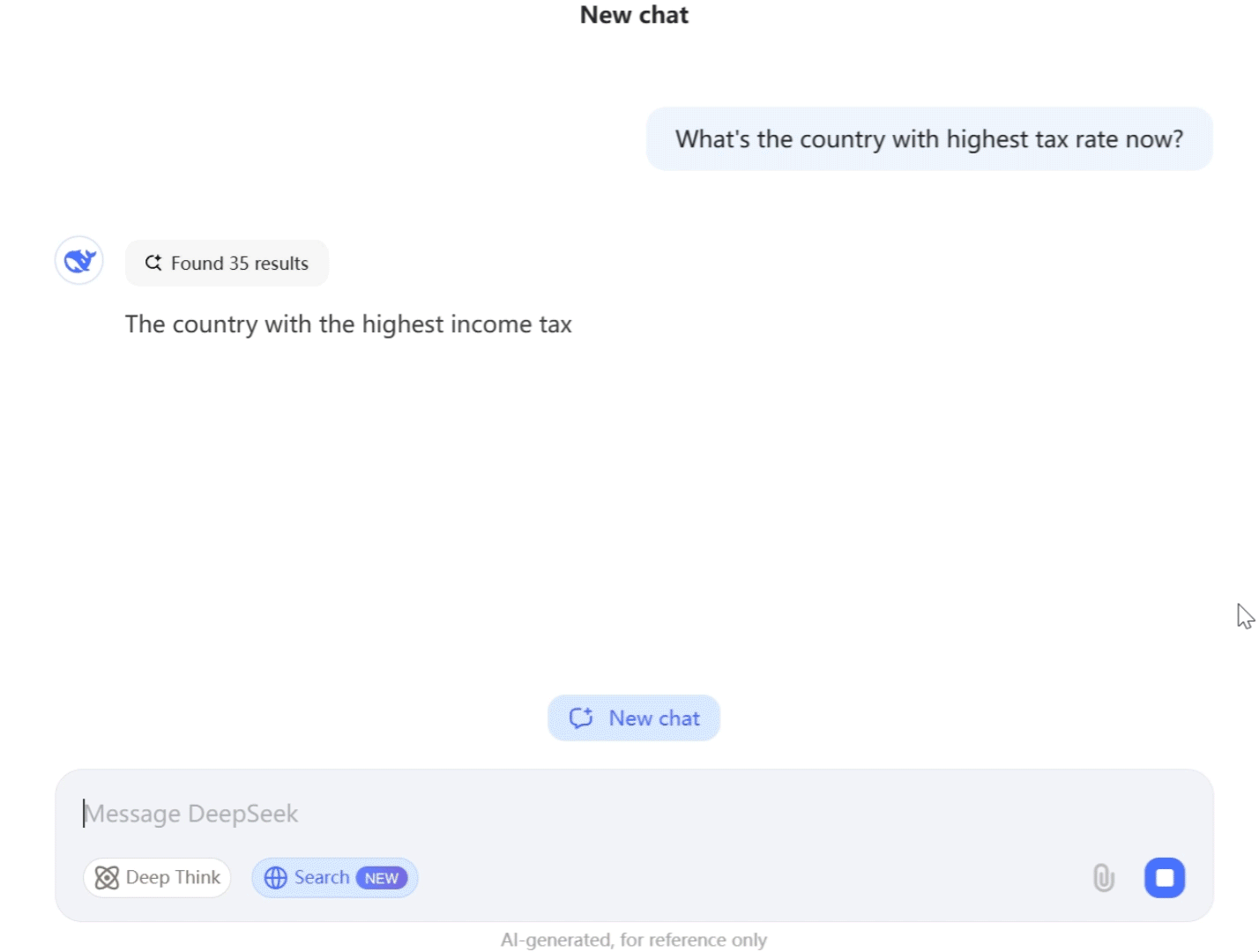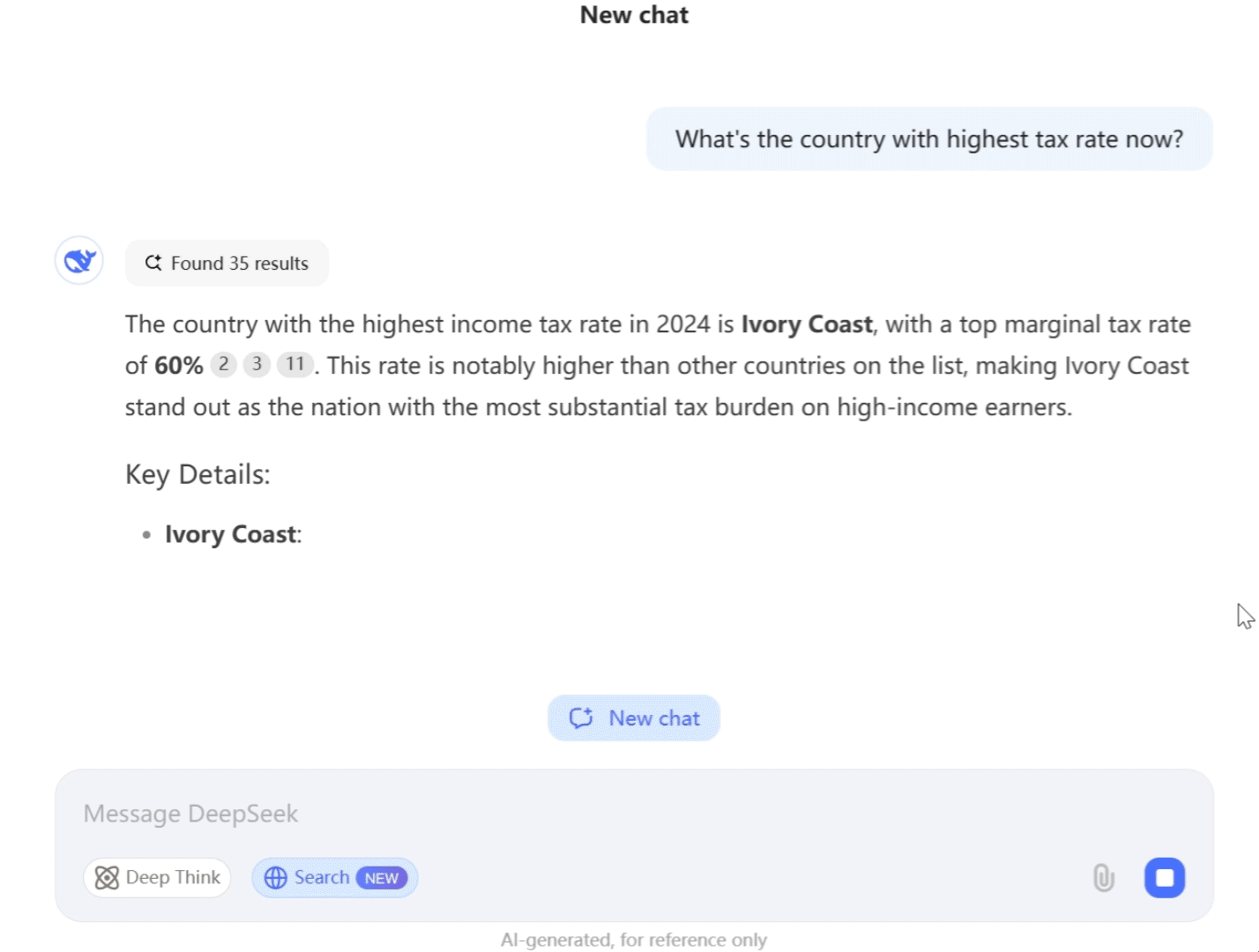
What is DeepSeek?

DeepSeek is a cutting-edge open-source AI platform and research lab founded in China in 2023. In a short time, this startup (based in Hangzhou and backed by the High-Flyer hedge fund has gained international recognition for its advanced generative AI models.
Unlike proprietary AI providers, DeepSeek focuses on developing efficient, open-source large language models (LLMs) that anyone can use or build upon. Its core offering is a versatile AI chatbot that competes with top global models like OpenAI’s GPT-4 – providing GPT-4-level capabilities in an open and cost-effective manner. The company offers a web chat interface, mobile app, and developer API for easy access to its models.
DeepSeek’s mission and approach have set it apart in the AI landscape. By iterating rapidly on open LLM releases, DeepSeek has matched or exceeded the performance of much larger closed models at a fraction of the training cost. In fact, DeepSeek famously claimed it built its flagship model for under $6 million – an order of magnitude less than what leading U.S. labs spend.

This combination of open accessibility and technical efficiency has made DeepSeek a serious new contender in AI. Its breakthroughs even caused a stir among industry observers: in early 2025, the debut of a DeepSeek model prompted U.S. tech stocks to tumble amid “Sputnik moment” concerns that China had leapfrogged the West in AI.
In short, DeepSeek is rapidly emerging as a global AI game-changer, delivering free AI chat and coding assistance that rivals the best from Big Tech.
Evolution of DeepSeek’s Models
Since late 2023, DeepSeek has released a rapid succession of open-source models, each building on the last. The DeepSeek model family includes both general-purpose LLMs and specialized offshoots, all aimed at pushing the envelope in capability, context length, and efficiency. Here’s an overview of DeepSeek’s notable models and their evolution:
DeepSeek Coder (Nov 2023)

The company’s first open-source model, specialized for programming tasks. It was released in parameter sizes of about 1.3B, 6.7B, and 33B, and trained on a curated corpus of code in over 80 programming languages.
DeepSeek Coder introduced long-context code generation with a window up to 16K tokens, enabling it to handle files and repositories far better than earlier code models.
DeepSeek LLM (Dec 2023)
The first version of DeepSeek’s general-purpose language model. It debuted with 7B and 67B parameter variants, trained on a massive 2 trillion token dataset spanning English and Chinese text. Despite being open, DeepSeek LLM was highly capable in broad language tasks, serving as the foundation for subsequent models.
DeepSeek-V2 (May 2024)
The second-generation LLM focused on improved performance and lower training cost. DeepSeek-V2 refined the architecture and training pipeline to be more efficient, setting the stage for larger-scale experiments. (Details on its parameter count were not publicly highlighted, but its refinements became evident in later versions.)
DeepSeek-Coder-V1.5 (mid 2024)
An interim upgrade to the coding model. By further pre-training the 7B Coder on a mix of natural language, code, and math data (an extra 2B tokens), DeepSeek produced Coder v1.5 with enhanced understanding of human instructions and math problems – all without sacrificing coding prowess. This proved the benefit of building coding models atop a strong general LLM core, yielding a smaller model that “maintains high-level coding performance but also exhibits enhanced natural language comprehension”.
DeepSeek-Coder-V2 (July 2024)
A massive leap in the coding series. Coder-V2 is a 236 billion-parameter model designed for the most complex coding challenges. It uses a Mixture-of-Experts (MoE) architecture – effectively having many expert sub-models – with about 21B parameters active per query.
This design yields an unprecedented 128,000-token context window for code, meaning it can read and generate across entire codebases or lengthy documents without breaking context.
DeepSeek-Coder-V2 was trained on an extra 6 trillion tokens of data (60% raw source code, 10% math, 30% natural language), covering 338 programming languages from common to niche. This enormous training regimen, combined with fine-tuning and reinforcement learning, produced what was then the most powerful open coding assistant available.
DeepSeek-V2.5 (Sept 2024)
A special “fusion” model that combined DeepSeek’s general and coding expertise. Essentially, V2.5 took the best of DeepSeek-V2 (general LLM) and DeepSeek-Coder-V2, integrating them into one model.
The result was a 238B-parameter MoE model (160 experts with 16B active) capable of both strong chat reasoning and coding. DeepSeek-V2.5 achieved top-tier performance across diverse benchmarks – math, coding, writing, even role-playing dialogues – making it a well-rounded AI assistant.
It also retained the 128k long context, pushing the limits of how much information an open model can juggle at once. An updated DeepSeek-V2.5-1210 version in Dec 2024 further boosted its math and coding accuracy.
DeepSeek-V3 (Dec 2024)
The third-generation LLM, representing a major scale-up. DeepSeek-V3 uses an advanced Mixture-of-Experts architecture with a staggering 671 billion parameters (spread across many experts). Like its predecessor, it supports a 128k token context. The MoE approach allows V3 to handle a wide range of tasks with specialized “experts” contributing to different queries, all while keeping inference efficient. DeepSeek-V3 demonstrated state-of-the-art open-source performance on general language tasks, validating the MoE strategy for large LLMs.
DeepSeek-R1 (Jan 2025)
The first-generation “reasoning” model that truly put DeepSeek on the global map. R1 is built on DeepSeek-V3’s architecture (671B params, 128k context) but is further refined for complex reasoning and problem-solving. Notably, DeepSeek-R1 was trained with novel large-scale reinforcement learning techniques to excel at reasoning tasks.
The researchers employed “reward engineering” – a carefully designed rule-based reward system – instead of purely neural feedback, allowing the model to develop advanced reasoning behaviors efficiently. The result was an open model that can directly compete with OpenAI’s best (their proprietary “o1” reasoning model) on challenging benchmarks. DeepSeek-R1’s debut was so impressive that it was compared to an “AI Sputnik moment” for the West, demonstrating that cutting-edge AI no longer belongs exclusively to a few big labs.
Janus-Pro-7B (Jan 2025)

Alongside R1, DeepSeek also released a vision-language model called Janus Pro. This 7B-parameter model can interpret images and generate descriptions or even create images, similar to OpenAI’s DALL-E or vision-enabled GPT-4. Janus (and the earlier DeepSeek-VL series) indicates DeepSeek’s expansion into multimodal AI, integrating vision with language.
Other Specialized Models
DeepSeek has shown its versatility with targeted models like DeepSeek-Math and DeepSeek-Prover. DeepSeek-Math builds off the 7B Coder (v1.5) and is continually pre-trained on a 120B-token math corpus (plus code and text) to tackle complex mathematical reasoning. DeepSeek-Prover is aimed at automated theorem proving in formal math: it was trained on synthetic proofs in the Lean 4 system to assist with formal verification tasks. These niche models underscore DeepSeek’s holistic approach – covering coding, math, vision, and more in its ecosystem.
In summary, within barely one year DeepSeek went from a newcomer to producing some of the most capable open-source LLMs across multiple domains. Each generation – from the original DeepSeek LLM and Coder to the latest V3 and R1 – brought significant leaps in model size, context length, and specialization.
DeepSeek LLM vs. DeepSeek Coder: Generalist and Specialist

Two of the most important pillars of the DeepSeek lineup are the aptly named DeepSeek LLM and DeepSeek Coder. These started as separate model series (for general-purpose chat and for programming assistance, respectively) but have also converged in interesting ways. Here’s a closer look at each:
DeepSeek LLM (General Model): DeepSeek’s core language model is designed for broad knowledge and natural conversation. The first DeepSeek LLM release (Dec 2023) offered a chat assistant that could handle open-ended questions, creative writing, translation, summarization, and more – similar to ChatGPT’s capabilities. Even the initial 7B and 67B versions proved remarkably competent, thanks to the huge bilingual training corpus and fine-tuning on helpful instructions.
For example, the 67B DeepSeek-LLM was observed by early users to be “really good at coding” as well, often producing well-structured solutions in code discussions:
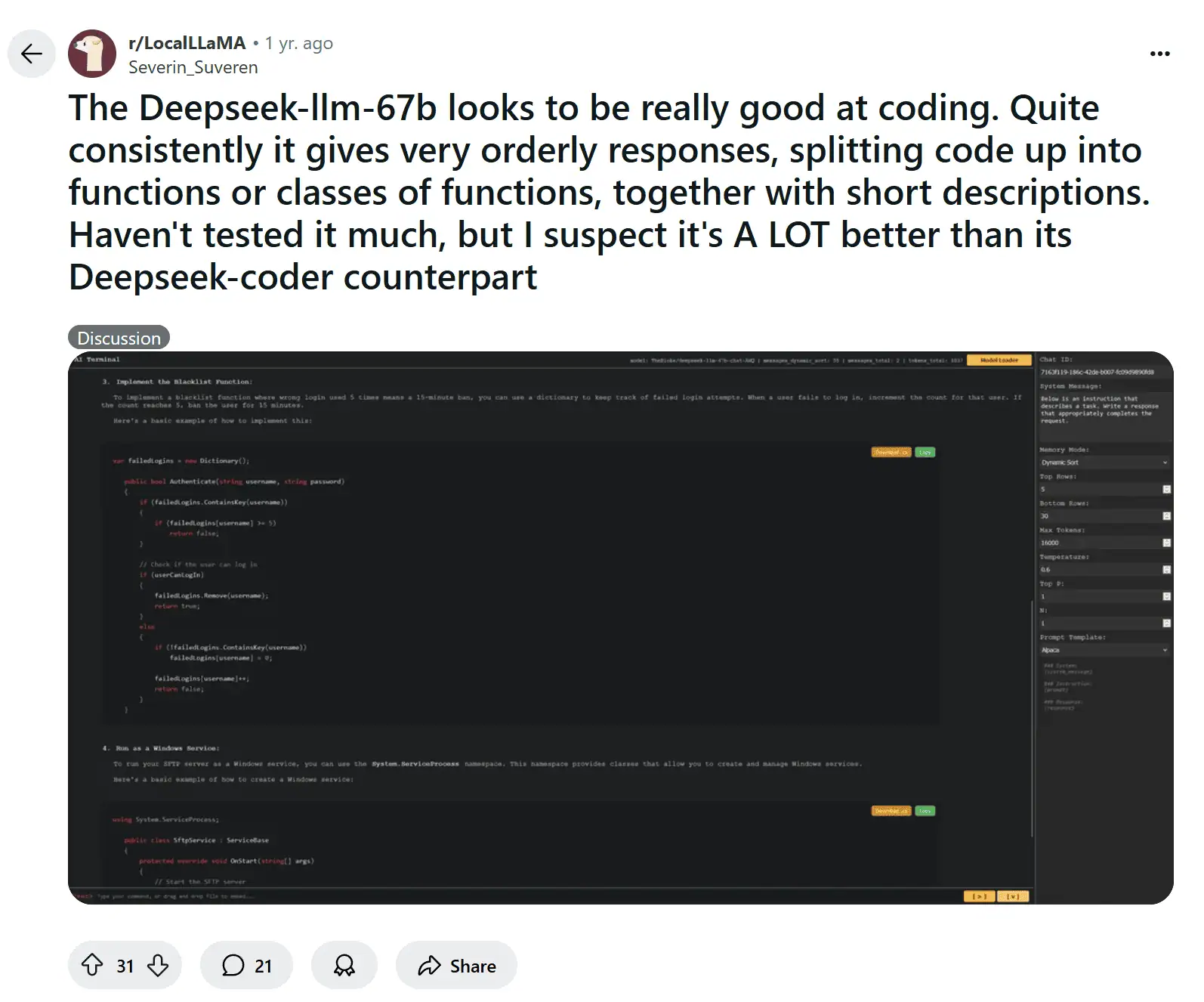
This hinted that the general model had learned coding to some extent from its data – a testament to the breadth of its training.
Over subsequent versions, the DeepSeek LLM became larger and smarter (V2, V2.5, V3 as discussed). The DeepSeek-V3 general model in late 2024 showcased mixture-of-experts techniques that allow specialization without sacrificing generality.
This architecture helped it excel across tasks: from complex reasoning to open-domain Q&A. Notably, DeepSeek’s models maintain strong performance in both English and Chinese, reflecting their dual-language training.
The generalist LLM is also the foundation for many derivative models – as DeepSeek’s team noted, a robust base model is crucial because “to effectively interpret and execute coding tasks, [a model] must also possess a deep understanding of human instructions”.
DeepSeek Coder (Coding Specialist): DeepSeek Coder is a series of models finely tuned for programming help – analogous to OpenAI’s Codex or Meta’s Code Llama, but open-source. Introduced in November 2023, the first DeepSeek-Coder was trained on an ambitiously large set of code repositories (with rigorous filtering for quality) and even incorporated a Fill-in-the-Middle (FIM) objective to learn to insert code into existing context.
This gave it a powerful ability to autocomplete and refactor code in ways standard predictors could not. The initial Coder models (1.3B to 33B size) were benchmarked on coding challenges and already outperformed other open models of similar scale.
In fact, the 6.7B DeepSeek-Coder was shown to match the performance of a 34B parameter Code Llama model, thanks to the high-quality training data and techniques. This efficiency – smaller models beating much larger ones – highlighted DeepSeek’s effective training regimen.
With DeepSeek-Coder-Instruct versions, the team also applied instruction tuning (using formats like Alpaca) to make the model better at following natural-language prompts for coding tasks. By early 2024, their 33B Coder-Instruct was outperforming OpenAI’s GPT-3.5 Turbo on many coding benchmarks, showcasing an open model reaching parity with a popular closed API.
The Coder v1.5 update further bolstered the model’s comprehension by injecting general knowledge (from DeepSeek-LLM’s checkpoint).
The pinnacle is DeepSeek-Coder-V2, which surpasses even GPT-4 Turbo on code generation and math problem benchmarks. This 236B-parameter giant can handle virtually any programming language (over 300 languages supported) and solve complex tasks that were once exclusive to top proprietary models.
For instance, Coder-V2 achieved leading scores on challenges like HumanEval (writing correct functions from specs) and GSM8K (math word problems) – domains that require reasoning as well as coding skills.
It also introduced reinforcement learning fine-tuning (using a technique called Grouped Relative Policy Optimization) to further refine its coding responses. Despite its size, DeepSeek released Coder-V2 openly on platforms like Hugging Face, along with a smaller 16B variant for those with less compute. This means developers everywhere can experiment with a state-of-the-art coding AI at no cost, a development practically unheard of until DeepSeek arrived.
Integration of LLM and Coder: A unique aspect of DeepSeek’s ecosystem is how the general LLM and Coder models have begun to merge capabilities. DeepSeek-V2.5 was explicitly a blend of chat and coder expertise, intended to serve “all your work and life needs” in one model. Likewise, the flagship DeepSeek-R1 reasoning model, while not code-specific, is proficient at programmatic reasoning and can write code to solve problems (a technique known as program-aided reasoning). The takeaway for users is that DeepSeek’s AI can seamlessly switch between natural language dialogue and coding assistance.
For example, you might be chatting with DeepSeek about an idea and then ask it to generate a snippet of Python – and it can do both in one conversation. This versatility, combined with the models’ huge context windows (allowing entire codebases or lengthy texts to be given as input), makes DeepSeek’s tools extremely powerful for developers, researchers, and general users alike.
Capabilities and Performance Benchmarks
One of the reasons DeepSeek has drawn so much attention is its exceptional performance on standard AI benchmarks, despite being open-source. Through a combination of massive training data, innovative architecture (MoE), and fine-tuning strategies, DeepSeek models have racked up impressive results:
- Coding Benchmarks: DeepSeek-Coder models dominate many coding tests. The 33B Coder beat OpenAI’s GPT-3.5 Turbo in code generation tasks, demonstrating higher accuracy in writing correct solutions for programming challenges. With the advent of Coder-V2, DeepSeek claimed the top spots on coding leaderboards, even edging out GPT-4 Turbo and other closed models on problems requiring both coding and reasoning. For example, Coder-V2 leads on GSM8K (a math word-problem set often used to gauge reasoning) and performs strongly on HumanEval and MBPP (code-writing tasks). The model’s fill-in-the-middle training also lets it excel at code completion tasks where it needs to insert code into existing files – something most LLMs struggle with.
- General Language Benchmarks: DeepSeek’s general LLMs have shown competitiveness with the best open models and even some closed models. Community evaluations indicate that DeepSeek-V2.5 and V3 rank among the top open-source LLMs on tests like MMLU (knowledge questions), Big-Bench tasks, and more. In fact, on some leaderboards, DeepSeek-V2.5’s performance was comparable to or better than much larger models like Meta’s rumored LLaMA 3 (405B) in certain categories. Its strength in coding tasks is particularly noted to significantly outscore rivals like Mistral Large (another MoE-based open model) on coding benchmarks. While precise benchmark numbers vary, the consensus is that DeepSeek models are at the forefront of open AI performance.
- Reasoning and Math: Thanks to the R1 model and specialized variants, DeepSeek also shines in logical reasoning and mathematics. DeepSeek-R1 was reported to match OpenAI’s top “o1” model on complex reasoning benchmarks, which implies human-level performance on tasks like multi-step logic puzzles and inference. Moreover, DeepSeek’s inclusion of a “Math” corpus and even a dedicated DeepSeek-Math model means it handles math word problems and calculations better than most peers. Coder-V2’s training on a 10% math dataset gave it a boost on math-heavy benchmarks like GSM8K and math-oriented coding challenges. Users have found that DeepSeek can follow through multi-step solutions or even write code to solve math problems, reflecting strong numerical reasoning ability.
- Multilingual and Domain Expertise: By training on both English and Chinese (and coding in hundreds of languages), DeepSeek models are inherently multilingual. They can converse or generate content in either language fluently, and likely handle other languages reasonably well due to the diverse pretraining data. In the coding realm, supporting 300+ programming languages means even esoteric languages (from Python and C++ to COBOL or VHDL) are within DeepSeek’s grasp. This breadth is quite unique – for instance, DeepSeek’s coding model can assist with legacy languages or hardware description languages that other AI copilots often don’t cover. The wide training also imbues knowledge across domains (e.g. it has seen legal text, scientific papers, etc.), making it a well-rounded model that can handle niche queries.
- Long Context Processing: A standout capability of DeepSeek is handling extremely long contexts. Later models (Coder-V2, V2.5, V3, R1) all boast a context window up to 128,000 tokens. In practical terms, that means a single prompt could include hundreds of pages of text or code. This is far beyond the context length of most models (OpenAI’s GPT-4 tops out at 32K tokens for its extended version). With such a long context, DeepSeek can be used to analyze lengthy documents, entire books, or large multi-file code projects in one go – enabling use cases like comprehensive report summarization or cross-file code refactoring. Early testing indicated that while the model can ingest 128K tokens, its most reliable performance is within somewhat shorter spans (e.g. 16K-32K), after which quality might gradually taper. Nonetheless, the ability to even attempt such long inputs is a major innovation and highly valuable for tasks like processing logs, archives, or big codebases.
In summary, DeepSeek’s performance demonstrates that open-source models can compete with, and even surpass, closed models on many fronts. By making these benchmarks public and releasing the model weights, DeepSeek has enabled the community to verify the claims. For instance, independent projects integrated DeepSeek into evaluation pipelines and confirmed its strong results: one Reddit user noted that “on [code] leaderboards, DeepSeek V2.5 significantly outscores Mistral Large 2, and in my experience it’s able to keep pace with the best closed offerings (though not as strong)”. Such community feedback reinforces that DeepSeek has indeed delivered top-tier AI performance accessible to all.
Use Cases and Applications
DeepSeek’s models are versatile and have been applied to a wide range of use cases. Because the DeepSeek LLM is a general chatbot and the DeepSeek Coder is a specialized developer assistant, together they cover most tasks one would expect from an AI like GPT-4 or ChatGPT – and then some. Here are some key applications:
Conversational Assistant:
At its core, DeepSeek provides an AI chat assistant for everyday queries and creative needs. Users can chat with DeepSeek (via the web interface or app) to ask general knowledge questions, get explanations of complex topics, brainstorm ideas, or have casual conversations.
Thanks to training on diverse web text and instruction tuning, DeepSeek can summarize articles, translate languages, draft emails or essays, and even engage in role-play or storytelling scenarios. It is essentially a free alternative to ChatGPT that one can use without signup.
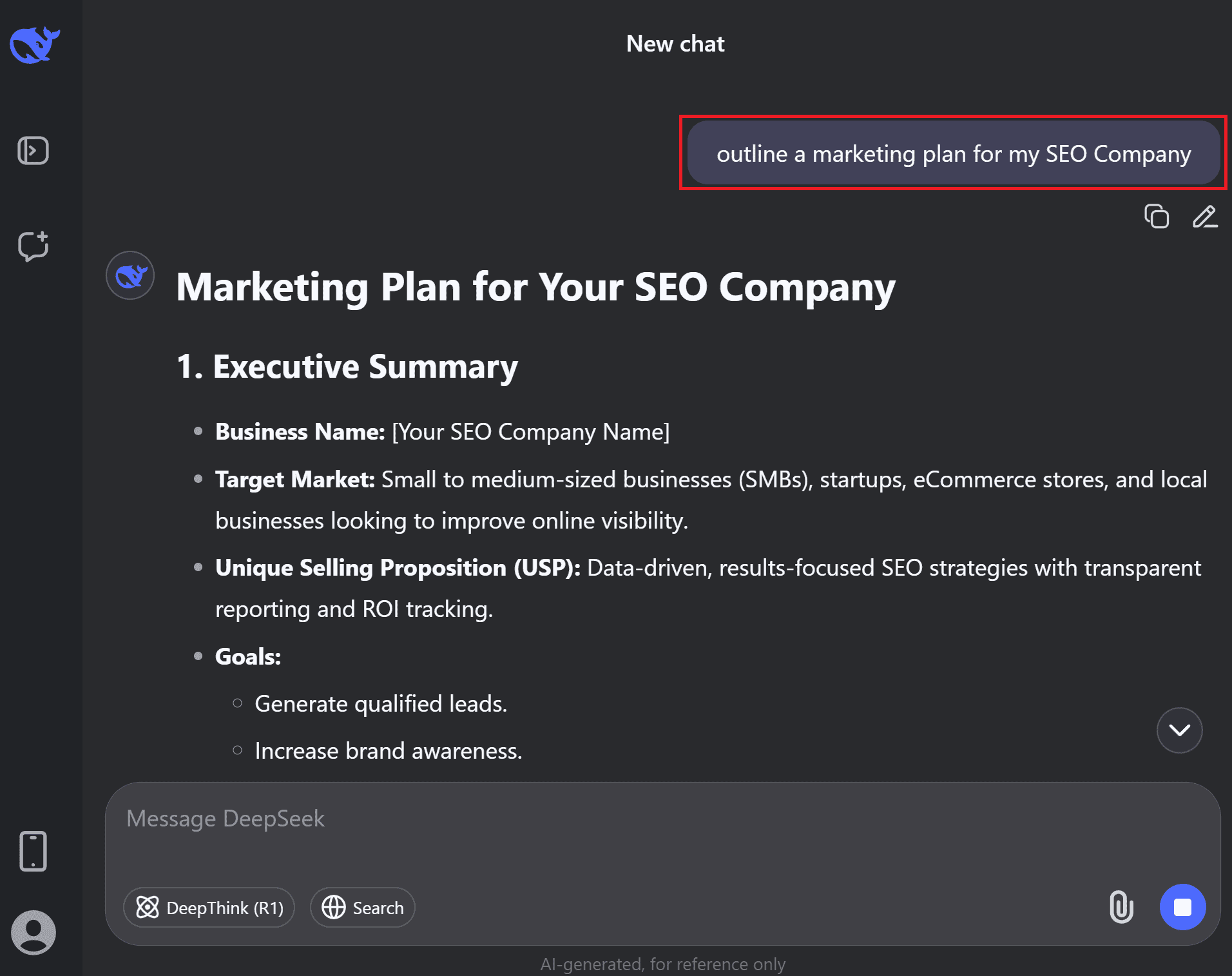
For example, a user might ask DeepSeek to outline a marketing plan or to rewrite a paragraph in simpler terms – tasks it handles with ease, much like other advanced LLM-based assistants.
Coding Help and Software Development:
With the DeepSeek-Coder models integrated, DeepSeek is extremely useful for programmers. It can act as an AI pair programmer, helping write code, debug errors, and generate project boilerplate.
Developers can prompt DeepSeek for code snippets in a desired language or ask it to explain what a piece of code does. Because it was trained on repository-level code, DeepSeek can handle multi-file contexts and understand how functions and classes relate across a codebase (within the large context window).
Use cases include: generating functions or classes from scratch, completing unfinished code, suggesting improvements or refactoring, and even writing unit tests. It supports not just mainstream languages (Python, JavaScript, Java, C# etc.) but many less common ones, making it a handy tool for maintaining older systems (imagine getting AI help on a piece of COBOL or Verilog code!).
Its coding competence is on par with high-end tools – for instance, DeepSeek-Coder can solve difficult LeetCode programming problems and data science tasks, which is invaluable for developers prepping for interviews or tackling algorithmic challenges.
The open-source community has embraced this: third-party tools like Aider (an AI coding assistant) have integrated DeepSeek models as a backend option, allowing developers to use DeepSeek for code editing tasks in their own IDEs. This integration has shown that DeepSeek’s suggestions can significantly speed up coding tasks and catch issues early, boosting developer productivity.
Data Analysis and Math:
Given DeepSeek’s strong reasoning and the specialized math model, it can assist with data analysis, solving math problems, and even writing code to analyze data. A user could input a dataset (in text or CSV form within the context window) and ask DeepSeek to derive insights or perform calculations.
The model can write small programs or formulas to filter and compute results, effectively acting like a data science assistant. Its high performance on math and reasoning benchmarks means it can tackle logical puzzles, financial calculations, or physics problems by breaking them down step-by-step.
For instance, one could feed a complex word problem or a set of equations into DeepSeek, and it will attempt to reason out the solution (even generating code to do so if needed).
Content Creation:
Content writers and marketers can leverage DeepSeek for generating high-quality text. Whether it’s drafting blog posts, social media captions, product descriptions, or even short stories and poems, DeepSeek’s general LLM has the creativity and knowledge to produce coherent and context-appropriate content. Users have noted its outputs are comparable to top-tier models in fluency. It’s also useful for editing and polishing text – you can ask DeepSeek to proofread a paragraph or change the tone of a draft (make it more formal, more friendly, etc.). Because it’s open-source, there are fewer usage limits, so one could generate longer pieces of content without the strict token limits imposed by some commercial APIs.
Education and Tutoring:
DeepSeek can serve as a personal tutor or explainer across various subjects. Its training on large knowledge corpora means it can answer questions in history, science, literature, etc., often with detailed explanations. Students can use it to clarify concepts (“Explain Newton’s laws in simple terms”), get help with homework problems (with the caveat that it should be verified), or even to practice foreign languages (given its bilingual strengths).
The model’s instruction-following nature allows it to adapt to educational prompts, for example: “Act as a tutor and walk me through solving this calculus problem step by step.” It also has some capability for logical reasoning puzzles and can engage in Socratic questioning to guide learners, thanks to the reinforcement learning on reasoning used in R1.
Multimodal Use (Vision and Beyond):
With the introduction of models like Janus-Pro, DeepSeek has started to handle images. This opens up use cases such as describing images (for accessibility), analyzing the content of a picture, or even generating images from prompts (if the model supports generative vision, though details on Janus suggest it’s mainly for understanding images).
A user could potentially paste a link to an image and ask DeepSeek to interpret it or answer questions about it. This multimodal ability is still emerging, but it aligns with the trend of AI assistants that can see and hear. We can expect DeepSeek to expand in this direction, bridging text and other data modalities.
In all these applications, a key advantage is that DeepSeek is open and free to use. Individuals and businesses can deploy DeepSeek models locally or via cloud without hefty fees. This has spurred a growing community of developers incorporating DeepSeek into their workflows – from AI customer support chatbots, to research analysis tools, to hobby projects. Its wide range of capabilities means it can be a one-stop solution for many AI needs: one day you might use DeepSeek to fix a bug in your code, and the next day to draft a newsletter or translate a document.
How DeepSeek Stacks Up Against Other LLMs
Given DeepSeek’s achievements, it’s natural to compare it to other prominent LLMs, both open-source and proprietary. Here are some points of comparison that highlight what makes DeepSeek unique:
Open-Source vs Proprietary
DeepSeek stands out for its commitment to open-source releases. Unlike OpenAI’s GPT-4 or Google’s PaLM, which are closed models accessed only via paid APIs, DeepSeek publishes its model weights openly on platforms like GitHub and Hugging Face. This “mostly open source” approach means researchers and developers can inspect, run, fine-tune, and integrate DeepSeek models without restriction. It flips the usual business model – instead of charging per token, DeepSeek provides free access and even allows commercial use of its models.
This has put competitive pressure on proprietary providers, since DeepSeek offers a viable alternative at a fraction of the cost for users. For example, OpenAI’s top reasoning model (o1) costs an order of magnitude more to develop and use than DeepSeek-R1.
DeepSeek’s open policy has been hailed by the community and simultaneously raised concerns in some circles (with debates about safety and misuse, given anyone can download a powerful model). Nevertheless, it has democratized access to GPT-4-level AI in a way that few others have.
Efficiency and Cost
DeepSeek’s engineering focus on efficiency is a major differentiator. Through clever training techniques (like reinforcement learning, reward engineering, and knowledge distillation), DeepSeek achieved top performance with less computing resources. As mentioned, their R1 671B model was trained for under $6M, whereas models like GPT-4 reportedly involve tens or hundreds of millions in compute spend.
Additionally, DeepSeek has shown that smaller models can punch above their weight: e.g., a 6.7B DeepSeek model matching a 34B competitor, or a 33B model outperforming a popular 175B (GPT-3.5) on coding. This focus on efficiency not only makes AI development more accessible but also suggests a path toward running powerful models on more modest hardware.
While Big Tech models often require fleets of high-end GPUs, DeepSeek’s distilled versions (like a 7B or even 1.5B param model with distilled knowledge) can run on a single server or even high-end PC – bringing AI assistance closer to offline or private deployments.
Model Architecture
DeepSeek has been a pioneer in using Mixture-of-Experts at scale in open models. Other open projects like Google’s Switch Transformer or more recent ones (e.g., Mistral’s MoE) exist, but DeepSeek’s V3 and V2.5 are among the largest MoE models publicly available.
This architecture gives DeepSeek an edge in specialization; it can allocate different “expert” submodels for different tasks, potentially capturing a wider range of skills without simply scaling up one monolithic network. In contrast, Meta’s LLaMA series or other open models (Falcon, Mistral, etc.) are mostly dense Transformer models. MoE models are more complex to train and serve, but DeepSeek demonstrated it effectively.
The 128k context is another architectural edge – achieved by extending positional embeddings (RoPE) and optimizing attention for long sequences. Few other models approach that context length in 2024/2025; most others top out at 8k or 32k tokens.
OpenAI’s GPT-4 has 32k in its extended version, and Meta’s long-context models (if any) were not near 128k. This means for tasks involving large documents, DeepSeek is in a league of its own.
Multilingual and Multimodal
Compared to many Western models which are primarily English-centric, DeepSeek’s bilingual training (English and Chinese) gives it a broader perspective out-of-the-box. It can cater to a huge user base in Mandarin-speaking communities with native-level fluency, something GPT-4 or LLaMA might require additional fine-tuning to achieve.
Moreover, DeepSeek releasing a vision model (Janus-Pro) indicates it’s joining the ranks of OpenAI (with DALL-E, Vision GPT-4) and Google (with Gemini likely multimodal) in pursuing multimodal AI. Many open-source efforts haven’t yet delivered strong vision-language models, so DeepSeek’s work here could be significant in the open realm.
Benchmark Leader and Rapid Iteration
DeepSeek has gained a reputation in the AI community for quickly climbing to the top of leaderboards for open models. Each release (Coder, V2, V2.5, R1) often came with claims of state-of-the-art results on certain benchmarks, and these were largely validated by independent testers.
For example, after DeepSeek-V2.5 came out, discussions on AI forums noted it was consistently outperforming rivals like Meta’s LLaMA 3-70B and 405B on key benchmarks . DeepSeek’s swift iteration cycle (new models or major updates every few months) contrasts with bigger players that have longer development cycles.
This agility is part of what makes DeepSeek a disruptive force – it keeps narrowing any gap that exists between open and closed models in real time, and sometimes surpasses the closed models before they can respond.
Use in the Wild
By virtue of being open, DeepSeek models have been popping up in various tools and services. We mentioned the Aider integration for coding; another example is that DeepSeek models can be run locally via applications like Ollama or text-generation-webui, giving enthusiasts personal AI chatbots that do not rely on an external API.
In contrast, closed models like OpenAI’s require internet access and come with usage restrictions. However, one should note that running something like DeepSeek-V2.5 or V3 is resource-intensive (due to the model’s size). So while it’s open, not everyone can deploy the largest versions on a laptop – one might use cloud GPUs or wait for smaller distilled versions.
This is where DeepSeek’s strategy of releasing scaled-down models (e.g. 16B Coder variant, or the distilled 1.5B reasoning model) is clever: it ensures there are accessible options for the community.
In essence, DeepSeek has positioned itself as the open-source answer to the AI giants. It provides similar capabilities (and in some cases superior, like context length or coding breadth) while fostering a community-driven development model.
This has significant implications: on one hand, it accelerates innovation globally by allowing anyone to build on top of cutting-edge models; on the other hand, it raises competitive pressure on commercial AI providers and even policy concerns about the proliferation of advanced AI (some organizations have banned DeepSeek citing data privacy or security, given it’s based in China and user data might be stored there).
Regardless, from a purely technological and accessibility standpoint, DeepSeek’s impact is largely positive – it has opened up high-end AI capabilities to the world.
Community Reception and Future Outlook
The AI developer community has been both excited and intrigued by DeepSeek. Many see it as a breath of fresh air in the LLM space, proving that top-notch models need not be locked behind corporate walls. On forums like Reddit and in open-source circles, users have shared success stories and tips for using DeepSeek models.
For example, one user reported that the DeepSeek-LLM 67B model consistently produced well-structured code solutions, splitting problems into clear functions – a sign of strong coding ability emerging from a general model. Others have compared notes on DeepSeek’s performance, noting that “benchmarks have pretty much always had DeepSeek superior to [comparable models] for coding” and that even if you can’t run the huge models locally, the results are worth tapping into via an API or community demo.
The open-source AI community has also contributed back to DeepSeek’s ecosystem. People have fine-tuned the models on their own datasets, shared improvements, and built tools around them (from chatbot UIs to VSCode plugins for code completion).
DeepSeek’s availability on Hugging Face Hub has facilitated this; models like the 7B and 33B variants have tens of thousands of downloads, indicating robust interest and usage in the wild. This feedback loop – where users can directly use and stress-test the model – likely helps DeepSeek iterate even faster, focusing on real-world issues and demands.
Looking ahead, DeepSeek appears poised to continue its rapid development. The stated goal is to pursue artificial general intelligence (AGI) in a responsible way. In practical terms, this means we might see DeepSeek models becoming even more generalized and capable of multi-step reasoning, decision-making, and tool use.
The R1 model already hinted at emergent reasoning behaviors (like the model autonomously learning to verify its answers). Future versions might build on this to improve reliability and factual accuracy – areas where even the best LLMs still falter at times.
We can also anticipate DeepSeek expanding its model lineup. Perhaps larger vision-language models, speech recognition or generation (to compete with OpenAI’s Whisper), and further specialized models for things like biomedical data or finance.
Given DeepSeek’s collaboration-friendly approach, it wouldn’t be surprising if they partner with or draw from other open efforts (for instance, adopting techniques from Meta’s latest research or collaborating with academic labs).
Conversely, other companies are now reacting to DeepSeek: shortly after R1’s release, Alibaba and AI2 announced new LLMs (Qwen-2.5 and Tülu-3) to keep pace. This competitive leapfrogging suggests a healthy race in the open-source AI realm, which ultimately benefits users.
For general users and organizations, DeepSeek represents a powerful new option. It matters because it proves that open-source AI can reach top-tier performance, potentially driving down costs and encouraging transparency in AI development.
It also offers an alternative in a world otherwise dominated by a few AI giants – bringing diversity and resilience (for example, those wary of relying solely on OpenAI or concerned about data governance have another choice in DeepSeek). As one tech analyst wrote, “DeepSeek is open source and free, challenging the revenue model of U.S. companies charging monthly fees for AI services” Source. That disruptive potential is a big part of why DeepSeek has been in headlines.
Conclusion
DeepSeek’s LLM and Coder models are trailblazing examples of open-source innovation in artificial intelligence. They combine state-of-the-art capabilities – from lengthy context handling and expert-level coding to multilingual fluency and advanced reasoning – with an open and collaborative spirit. For anyone interested in AI, DeepSeek is a development to watch closely.
It not only delivers immediate value (as a powerful AI tool accessible today) but also charts a path for how AI can evolve through shared progress.
Whether you’re a developer looking for a coding co-pilot, a researcher exploring AI’s frontiers, or just an enthusiast wanting the latest AI assistant at your fingertips, DeepSeek offers a glimpse of the AI future – one that is open, potent, and within everyone’s reach.


