DeepSeek-LLM is a cutting-edge large language model (LLM) that has emerged as a formidable open-source alternative to proprietary AI giants like GPT-4 and Claude.
Introduced by DeepSeek AI in early 2024, this model was built from scratch with a long-term vision of advancing open LLM capabilities.
It boasts massive scale and top-tier performance while remaining accessible to researchers and developers.
With multi-billion parameter variants, extensive training on diverse data, and novel architectural innovations, DeepSeek-LLM stands out for its high performance, cost efficiency, and open availability.
In this article, we explore DeepSeek-LLM’s features, how it compares to leading models such as GPT-4, Claude, and Google’s Gemini, and the use cases it empowers.
Key Features and Architecture of DeepSeek-LLM
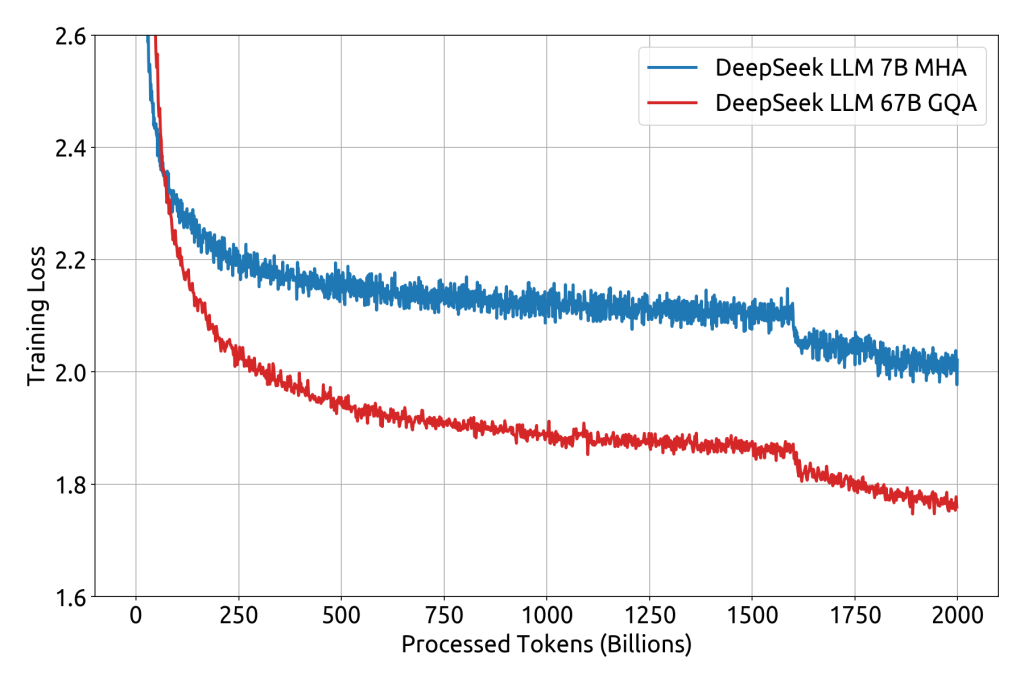
- Massive Scale with Mixture-of-Experts: DeepSeek-LLM’s latest iteration (DeepSeek v3) uses an innovative Mixture-of-Experts (MoE) architecture, packing 671 billion total parameters with 37 billion actively used per token. This MoE design allows the model to achieve the benefits of an extremely large network while only activating a fraction of the parameters for any given input. In practice, less than 6% of its parameters are engaged at once, drastically reducing computational costs without sacrificing capability. This efficient design means developers can leverage a model of unprecedented scale (over half a trillion parameters) with feasible resource requirements.
- Extensive Training Data: DeepSeek-LLM was trained on a colossal dataset of approximately 2 trillion tokens spanning English, Chinese, and other content. This diverse, long-term pretraining gives the model rich knowledge across domains and languages. By following scaling laws and continuously expanding the dataset, the DeepSeek team achieved a model that excels in general knowledge as well as specialized domains. Furthermore, supervised fine-tuning and preference optimization were applied to create chat-optimized versions (DeepSeek-LLM Chat), aligning the model’s responses with human instructions and preferences.
- Long Context Window (128K tokens): A standout feature is DeepSeek-LLM’s ability to handle extremely long input contexts – up to 128,000 tokens (roughly tens of thousands of words) in its latest version. This vastly exceeds the typical 4K-32K context of most models (GPT-4’s standard context is 8K, with an extended 32K option). Such a long context window allows DeepSeek to retain and reason over very large documents or codebases, making it ideal for tasks like processing lengthy reports, entire code repositories, or extensive conversations without losing track of earlier details. By comparison, other LLMs often max out at 32K–100K tokens, giving DeepSeek an edge in scenarios requiring deep long-form understanding.
- Advanced Attention Mechanisms: DeepSeek-LLM incorporates novel techniques like Multi-Head Latent Attention (MLA) to enhance how it processes input data. This mechanism enables the model to capture nuanced relationships and multiple aspects of input simultaneously, improving comprehension and context management. Combined with the MoE architecture, such innovations ensure that DeepSeek can focus computational power on the most relevant “expert” sub-networks for a given task, yielding task-specific precision and efficient processing.
- Open-Source and Accessible: Crucially, DeepSeek-LLM is released as an open-source project. Both the 7 billion and 67 billion parameter dense versions (and their chat-tuned variants) have been made publicly available for research and commercial use. The larger MoE-based “v3” model is also accessible via demos and downloadable weights. Open licensing means developers and organizations can use and even fine-tune DeepSeek without the hefty fees associated with proprietary models. This openness lowers the barrier to entry for advanced AI: smaller teams can deploy state-of-the-art language capabilities without prohibitive infrastructure or licensing costs. The DeepSeek community provides model checkpoints on Hugging Face and even intermediate training checkpoints, encouraging transparency and further innovation.
Performance and Benchmarks
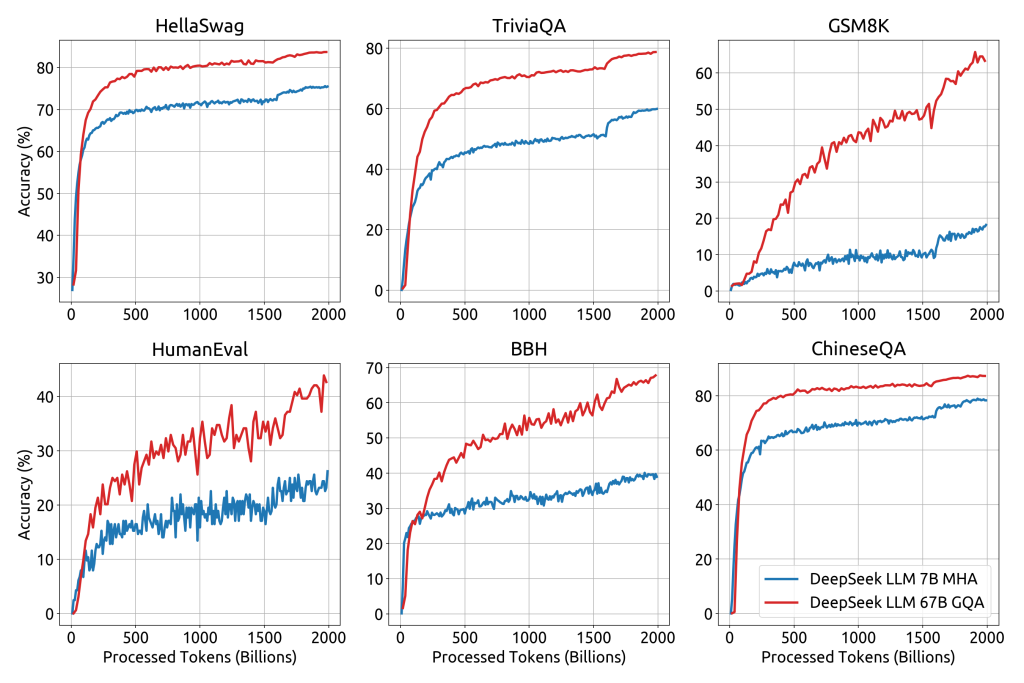
DeepSeek-LLM delivers impressive performance across a spectrum of challenging benchmarks, often rivaling or surpassing leading models of similar or greater size.
Some highlights of its performance include:
- Superior Reasoning, Coding, and Math: The flagship DeepSeek-LLM 67B model has demonstrated superior capabilities in complex reasoning tasks, code generation, and mathematics. Notably, it outperforms Meta’s LLaMA2-70B on benchmarks testing knowledge and reasoning. On coding challenges, DeepSeek achieved a HumanEval Pass@1 score of 73.78%, indicating it can generate correct solutions for nearly three-quarters of programming problems on the first attempt.

- For math and logical reasoning, it scored 84.1% on GSM8K (math word problems, 0-shot) and reached 32.6% on the MATH competition dataset (0-shot) – strong results that exceed many open models of comparable size. In fact, DeepSeek-LLM’s reasoning and coding proficiency is competitive with top-tier models, enabling it to tackle tasks like debugging code or solving complex quantitative problems with high accuracy.

- Bilingual Mastery (English and Chinese): Thanks to its bilingual training data, DeepSeek-LLM excels not just in English tasks but also in Chinese language understanding. Evaluations show that DeepSeek-LLM 67B Chat surpasses OpenAI’s GPT-3.5 (ChatGPT) in Chinese language tasks. This includes comprehension, question-answering, and writing in Chinese, an area where many Western models lag. The model’s strong multilingual foundation makes it attractive for global applications and for users who require AI assistance across languages.
- Benchmark Leader at Scale: DeepSeek’s developers report that the model attains state-of-the-art or competitive results on a wide range of benchmarks given its parameter scale. For example, DeepSeek v3’s mixture-of-experts approach with effectively 37B active parameters achieves performance comparable to leading closed-source models like GPT-4 on many tests. In open evaluations, DeepSeek-LLM 67B Chat has shown superior performance to GPT-3.5 in open-ended tasks, reflecting its advanced instruction-following and reasoning ability as a conversational agent.
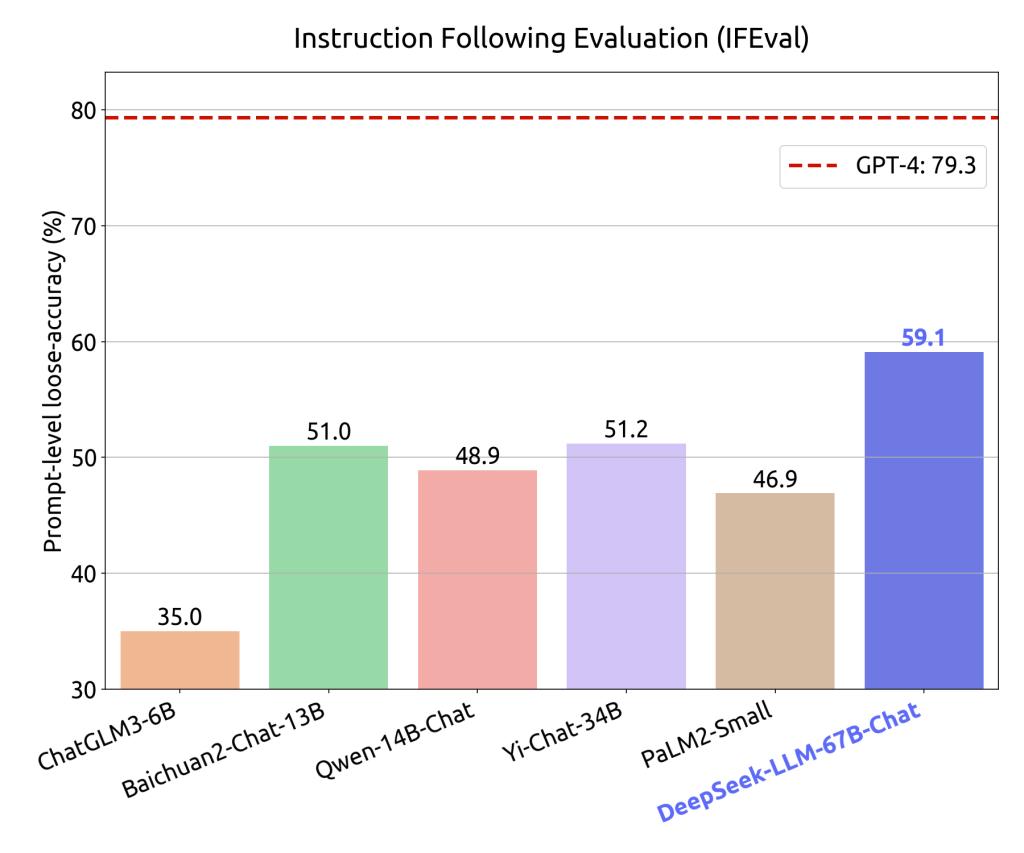
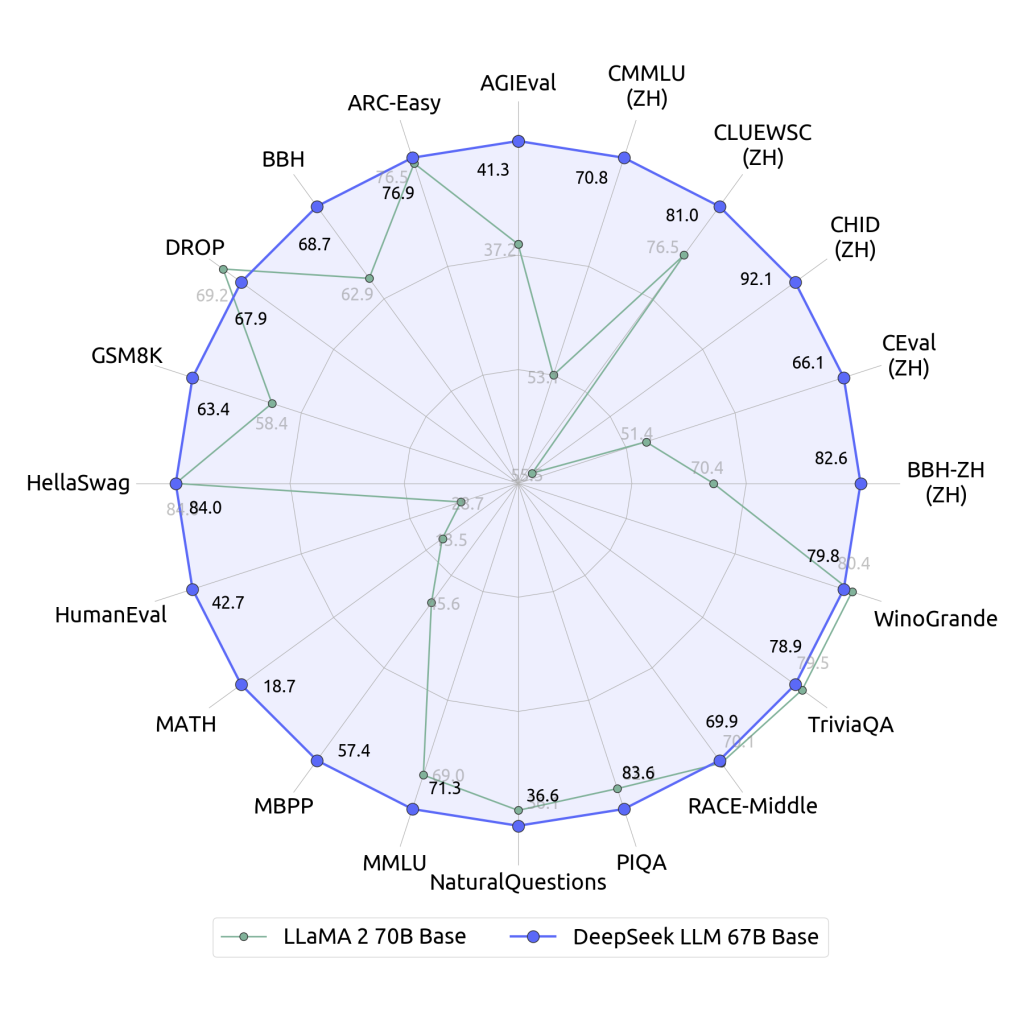
- An illustrative comparison is shown in the radar chart below, where DeepSeek-LLM 67B (blue) outperforms LLaMA2 70B (green) across multiple tasks including common sense reasoning (HellaSwag), coding (HumanEval), math (MATH dataset), and knowledge exams. These results underscore DeepSeek’s status as one of the most powerful open LLMs available.
- Training Efficiency: Impressively, DeepSeek-LLM reached these performance levels with relatively efficient training. The latest version was trained on 14.8 trillion tokens using just 2.788 million GPU hours on H800 GPUs – a fraction of the resources that comparable projects might consume. Techniques like FP8 mixed precision training and optimized cross-node MoE training contributed to this efficiency. For users, this efficiency translates to more accessible fine-tuning and deployment: DeepSeek’s inference cost per token is estimated 95% lower than typical proprietary models, thanks to activating fewer parameters and optimized design.
DeepSeek-LLM vs. GPT-4, Claude, and Gemini: How It Stacks Up
DeepSeek-LLM enters a landscape dominated by a few heavyweight AI models.
Here’s how it compares to some leading alternatives across architecture, performance, cost, and accessibility:
- GPT-4 (OpenAI): Widely regarded as the top performer in many NLP tasks, GPT-4 is a closed-source model with an estimated scale on the order of hundreds of billions to a trillion parameters (exact number not public). GPT-4 excels in reasoning, creativity, and complex problem-solving, and even has a multimodal vision-enabled variant (GPT-4V). However, it is proprietary – accessible only via OpenAI’s API or ChatGPT interface – and incurs significant usage costs. In comparison, DeepSeek-LLM approaches GPT-4’s prowess on many benchmarks while being completely open-source. For instance, DeepSeek can solve coding tasks and math problems at a level close to GPT-4’s, as evidenced by competitive scores on HumanEval and GSM8K. GPT-4 offers a standard 8K context (with an upscale to 32K or even 128K in limited beta models), whereas DeepSeek-LLM supports a 128K context window natively, allowing it to handle longer documents than even GPT-4’s usual capabilities. While GPT-4 might still hold the edge in certain nuanced reasoning or knowledge breadth (benefiting from proprietary training on unseen data), DeepSeek’s advantage lies in control and customization – users can host the model, fine-tune it to specific domains, and avoid API fees or data privacy concerns. Essentially, DeepSeek-LLM narrows the gap to GPT-4’s performance, making GPT-4-level AI more attainable to the wider community.
- Claude 2 (Anthropic): Claude 2 is Anthropic’s flagship LLM, known for its friendly conversational style, safety measures, and an exceptionally large context window (up to 100K-200K tokens). Like GPT-4, Claude is proprietary (accessible via API or Anthropic’s interface) and has around 70B+ parameters (Claude 2’s size is not officially stated, but it’s in the same ballpark as LLaMA2-70B). Compared to Claude, DeepSeek-LLM offers similar or better raw performance on many academic benchmarks and coding tasks. Claude’s standout 100K+ context is closely matched by DeepSeek’s 128K context support, meaning both can ingest very large inputs (e.g., book-length texts). However, Claude does not natively handle images or multimodal input, whereas DeepSeek’s focus (in the LLM version) is also text-only. In terms of accessibility, DeepSeek again has the upper hand by being open-source – organizations can deploy it internally without sharing data with an external API, an important consideration for privacy. Cost-wise, using DeepSeek could be far cheaper in the long run; instead of paying per token to Anthropic, one invests in computing once to run the model. For many developers, the trade-off is clear: if you need a controllable model with top-tier language ability and are willing to manage the infrastructure, DeepSeek-LLM is an attractive alternative to Claude’s closed but convenient service.
- Google Gemini: Google’s Gemini is a newer family of multimodal models (Ultra, Pro, Nano) aimed squarely at competing with GPT-4. Gemini Ultra reportedly surpasses GPT-4 on numerous benchmarks, achieving state-of-the-art results on MMLU, BigBench Hard, DROP, and more. It’s a multimodal system capable of text, image, and even possibly audio/video understanding, born from the merger of Google Brain and DeepMind expertise. In raw power, Gemini Ultra is rumored to have on the order of ≥500B parameters (one report mentions Gemini Pro at 540B) and advanced training leveraging techniques from AlphaGo and large-scale data. How does DeepSeek-LLM compare? While Gemini remains proprietary and limited to Google’s platforms (e.g., powering Bard), DeepSeek-LLM offers a free and open experience. In terms of performance, DeepSeek v3 claims to be comparable to leading closed models, which implicitly means it aims to reach the level of models like GPT-4 or Gemini in many tasks. For example, both Gemini and DeepSeek emphasize coding and reasoning: Gemini Ultra scores around 74% on HumanEval (codegen) vs DeepSeek’s 73.78% – essentially on par. The key differentiator is that Gemini is a Google product with likely superior multimodal abilities, whereas DeepSeek-LLM focuses on open development and community-driven improvement. Gemini might edge out DeepSeek in bleeding-edge benchmarks (reports indicate Gemini Ultra slightly beat GPT-4 on average), but those gains come at the cost of zero transparency. DeepSeek’s architecture (especially with MoE) is quite unique in the open space, and its performance is remarkable given a training budget far lower than what a tech giant can afford. For many use cases, DeepSeek-LLM can be a pragmatic substitute for Gemini/GPT-4, especially when budgets or data sovereignty demand an open solution.
- Other Open LLMs (LLaMA2, etc.): Against other open models like Meta’s LLaMA2, Falcon, or MosaicML’s MPT, DeepSeek-LLM distinguishes itself clearly. The 67B dense DeepSeek model surpasses LLaMA2-70B in multiple areas like coding and math. Its chat-tuned model is generally more capable than LLaMA2-chat in following instructions and multi-step reasoning (DeepSeek-Chat was observed to produce higher quality answers in evaluations). Unlike most open LLMs that use dense architectures, DeepSeek’s MoE version can scale to far larger parameter counts (hundreds of billions) while keeping inference cost manageable – something other open projects have not achieved at this scale. Additionally, DeepSeek’s 128K context and bilingual training give it practical advantages where others might falter (many open models support 4K-8K context by default and often need rope scaling to extend). In summary, DeepSeek-LLM currently represents one of the most advanced open-source LLMs, bridging the gap between community models and industry labs.
Use Cases and Applications
DeepSeek-LLM’s blend of high performance and open accessibility makes it suitable for a wide range of applications across industries:
- Software Development: With its strong coding abilities (HumanEval ~74% pass@1), DeepSeek-LLM is a boon for developers. It can serve as an AI coding assistant to generate functions or modules, help debug code by understanding error messages and code context, and even perform code review by analyzing large codebases (leveraging the long context). Organizations can fine-tune DeepSeek on their proprietary code to build custom pair-programmer assistants. The model’s multi-language support also means it can document code or discuss development issues in the user’s preferred language.
- Business Process Automation: DeepSeek is adept at understanding and generating natural language, which can streamline business workflows. For instance, it can power intelligent chatbots for customer service that handle complex queries, or process and analyze large corporate documents and reports to provide summaries and insights. Given its open nature, companies can deploy DeepSeek-LLM on-premises for tasks like reading confidential financial contracts or mining insights from internal knowledge bases – tasks where using a closed API might be undesirable. Its efficiency (MoE activation) also keeps operational costs down, making enterprise-scale automation more cost-effective.
- Data Analysis and Long-Form Content: Thanks to the 128K token window, DeepSeek-LLM can ingest and analyze very large text datasets. This is useful in data analytics and research – e.g., scanning through lengthy logs, scientific literature, or large datasets to answer questions. It can maintain coherence over long documents, making it ideal for summarizing books, compiling research findings, or drafting extensive reports while referencing source material directly within the prompt. Researchers could use DeepSeek to sift through hundreds of pages of academic papers and extract key points, something standard models might struggle with due to context limits.
- Education and Tutoring: As an AI with strong reasoning and language skills, DeepSeek-LLM can act as a personalized tutor. It can explain complex concepts step-by-step, solve academic problems (math, science, etc.), and provide detailed answers to student questions. Its training on both English and Chinese content enables it to assist learners in multiple languages. For example, DeepSeek could walk a student through a calculus problem or help practice a foreign language by engaging in conversation. Because it’s open-source, educational platforms can integrate DeepSeek without licensing hurdles, and even fine-tune it on specific curricula or pedagogical styles.
- Creative Content Generation: Like other LLMs, DeepSeek can generate human-like text for various creative needs – drafting articles, writing marketing copy, creating story narratives, or composing emails. With fine-tuning or prompting, it can adapt to different tones or domains. The advantage of DeepSeek is that content creators and businesses can use it without concerns about API usage limits or content filters imposed by providers (aside from abiding by the model’s license). This opens possibilities for custom AI writers that are tailored to a brand’s voice or an individual author’s style.
Conclusion
DeepSeek-LLM exemplifies a new wave of open-source AI models that combine state-of-the-art performance with community-driven development.
By leveraging massive training scales, novel architectures like Mixture-of-Experts, and thoughtful training strategies, DeepSeek has achieved results on par with some of the best proprietary models.
Importantly, it delivers this power in an accessible form – anyone can download the model or use it through provided demos, enabling a wider audience to experiment and innovate with advanced AI.
The model’s ability to handle long contexts and multiple languages further broadens its applicability, from enterprise applications to research and education.
While closed models like GPT-4, Claude, and Gemini still lead in certain areas, DeepSeek-LLM significantly narrows the gap and does so with a fraction of the cost and full user control.
Its open-source nature encourages collaboration: developers worldwide are able to contribute improvements, share fine-tuned versions, and adapt the model to niche use cases.
This fosters an ecosystem where AI progress is accelerated through openness.
As DeepSeek-LLM continues to evolve (with versions like DeepSeek v3 and beyond), it stands as a testament that open initiatives can drive AI forward in a way that is inclusive, transparent, and empowering for the broader tech community.
In summary, DeepSeek-LLM has firmly established itself as a top-tier large language model – one that offers an authoritative, cost-effective, and customizable AI solution for those looking beyond the big proprietary labs.